データモデリング¶
Note
この内容は検証中であり、検証の結果によっては記載内容を変更する可能性がある事に注意。
実際に検証した結果は、GitGubのソースコード を参照のこと。
検証のポイント¶
- Cassandraのテーブル構造
→リレーショナルデータベースとは違い、データ中心の設計アプローチをとるべきではない(と言われている)。データストアの特性が違うので、Cassandraで出来る事・出来ない事を整理して、適切な永続化のテーブル構造を考える。 - アプリケーションのデータモデリングの差異
→ エンティティオブジェクトはどのような構造をとるべきか - Spring Data Cassandraのマッピング機能とデータアクセスのお作法
→ どのような機能を持っていて、どういう実装方法が望ましいか - データモデリング設計の進め方
ユースケース¶
リレーショナルデータベースの場合のモデリングと対比するために、Spring Data JPAにおけるサンプルのユースケース を考える。
| ユースケース | リレーショナルモデルにおける エンティティ関連 |
|---|---|
| 全てのユーザを検索する | なし |
| 全ての住所を検索する | なし |
| 全てのメールアドレスを検索する | なし |
| 全てのグループを検索する | なし |
| 特定のユーザを検索する | なし |
| ログインIDをキーに特定のユーザを検索する | なし |
| 特定のユーザのアドレスを検索する | ユーザ : 住所 = 1 : 1 |
| 指定されたユーザのEmailの一覧を取得する | ユーザ : メール = 1 : N |
| 指定したグループ名を元にグループを検索する | なし |
| 特定の郵便番号を持つユーザ一覧を取得する | ユーザ : 住所 = 1 : 1 |
| 特定の郵便番号を持たないユーザ一覧を取得する | ユーザ : 住所 = 1 : 1 |
| 指定されたユーザの住所を追加する | ユーザ : 住所 = 1 : 1 |
| 指定されたユーザの住所を更新する | ユーザ : 住所 = 1 : 1 |
| 指定されたユーザの住所を削除する | ユーザ : 住所 = 1 : 1 |
| 特定のメールアドレスを持つユーザを検索する | ユーザ : メール = 1 : N |
| 指定されたユーザのメールアドレスを追加する | ユーザ : メール = 1 : N |
| 指定されたユーザをメールアドレスを含めて追加する | ユーザ : メール = 1 : N |
| 指定されたユーザのメールアドレスを更新する | ユーザ : メール = 1 : N |
| 指定されたユーザのメールアドレスを1件削除する | ユーザ : メール = 1 : N |
| 指定されたユーザのメールアドレスを全件削除する | ユーザ : メール = 1 : N |
| 指定したユーザが属するグループの一覧を取得する | ユーザ : グループ = N : N |
| 指定したグループに所属する全てのユーザ一覧を取得する | ユーザ : グループ = N : N |
| 指定したグループに所属しない全てのユーザ一覧を取得する | ユーザ : グループ = N : N |
| 指定したユーザを指定したグループに追加する | ユーザ : グループ = N : N |
| 指定したユーザをグループから除外する | ユーザ : グループ = N : N |
| 指定したグループを削除し、 ユーザが所属するグループの情報を更新する |
ユーザ : グループ = N : N |
| 指定されたユーザを削除し、グループのユーザ一覧を更新する | ユーザ : グループ = N : N |
データベースやクエリにおける相違点¶
RDBMSとCassandra¶
| 相違点 | RDBMS | Cassandra |
|---|---|---|
| 一貫性 | 強一貫性 | 設定可能な一貫性※1 |
| トランザクション | ACIDトランザクション | 軽量トランザクション |
| クエリ | SQL | CQL※2 |
| 一貫性レベル | 特徴 |
|---|---|
| ALL | クラスター内のすべてのレプリカ・ノードのコミット・ログとmemtableに 書き込まれる |
| EACH_QUORUM | 書き込みが、各データ・センターのレプリカ・ノードのクォーラム(過半数)の コミット・ログとmemtableに書き込まれる |
| QUORUM | 書き込みが、すべてのデータ・センターのレプリカ・ノードのクォーラム (過半数)のコミット・ログとmemtableに書き込まれる |
| LOCAL_QUORUM | 書き込みが、コーディネーター・ノードと同じデータ・センターにある レプリカ・ノードのクォーラム(過半数)のコミット・ログとmemtableに 書き込まれる |
| ONE | 書き込みが、少なくとも1つのレプリカ・ノードのコミット・ログとmemtableに 書き込まれる |
| TWO | 書き込みが、少なくとも2つのレプリカ・ノードのコミット・ログとmemtableに 書き込まれる |
| THREE | 書き込みが、少なくとも3つのレプリカ・ノードのコミット・ログとmemtableに 書き込まれる |
| LOCAL_ONE | ローカル・データ・センターの少なくとも1つのレプリカ・ノードに 書き込みを送信し、 確認応答がある |
| ANY | 書き込みが、少なくとも1つのノードに書き込まれる。パーティション・キーの すべての レプリカ・ノードがダウンしていても、 ヒンテッド・ハンドオフが書き込まれれば、書き込みを成功と見なす。 |
| 一貫性レベル | 特徴 |
|---|---|
| ALL | すべてのレプリカが応答した後に、レコードを返す。1つでもレプリカが 応答しないと、読み取り操作は失敗する。 |
| EACH_QUORUM | 読み取りが、各データ・センターのレプリカ・ノードのクォーラム (過半数)で読み取られる。 |
| QUORUM | すべてのデータ・センターのクォーラム(過半数)のレプリカが応答したら、 レコードを返す。 |
| LOCAL_QUORUM | コーディネーター・ノードが報告された際に現在のデータ・センター内のクォーラム (過半数)の|br|レプリカが応答したら、レコードを返す。 |
| ONE | スニッチによって定まる最も近いレプリカから応答を返します。デフォルトでは、 他のレプリカとの|br|整合性を維持するために、読み取りリペアが バックグラウンドで実行される。 |
| TWO | 最も近い2つのレプリカから最新のデータを返す。 |
| THREE | 最も近い3つのレプリカから最新のデータを返す。 |
| LOCAL_ONE | ローカル・データ・センターの最も近いレプリカからの応答を返す |
| SERIAL | 新しい追加や更新を提示することなく、現在の(そしてコミットされていない 可能性がある)データの状態を読み取ることができる。SERIALの読み取りにおいて 進行中のコミットされていないトランザクションが見つかった場合は、 読み取りの一環としてそのトランザクションがコミットされる。 |
| LOCAL_SERIAL | SERIALと同じだが、データ・センターに限定される。 |
| No | 特徴 |
|---|---|
| 1 | 結合や外部キー、副問合せのサポートがない → 必要に応じてテーブルを非正規化、マテリアライズドビューを使用する。 |
| 2 | GROUP BY等集約関数が標準で存在しない。Cassandra3以降、ユーザ定義関数はサポート。 → アプリの中でロジックとして実装する |
| 3 | WHERE句でプライマリキー以外を使用するにはインデックスが必要 → セカンダリインデックスを作成したり、マテリアライズドビューを使用する。 |
| 4 | データ型でCollectionをサポート。1:n関連に相当する有限のデータはCollectionを利用する。 センサーデータのような無限にデータが増えていく場合は、ノードを分散させるために、 複合プライマリーキーを使用する。 → 必要に応じて、テーブルを非正規化する。 |
| 5 | 更新の条件指定はプライマリキーのみに限定される アプリの中でロジックとして実装する。 |
| 6 | “OR”、”NOT”といった論理演算子はなく、ANDのみに限定される → アプリの中でロジックとして実装する |
| 7 | 日付型の演算時可能な表現が異なる → アプリの中でロジックとして実装する。 |
| 8 | 重複したキーのインサートはアップデートとして扱われる |
Spring Data Cassandraを使用したユースケースの実装¶
Spring Data JPAの例 との比較のために類似のユースケースを勘案して、解説する。実際に作成したサンプルは GitHub を参照のこと。
エンティティクラスの作成¶
テーブルを表現するアノーテションを付与したエンティティクラスを作成する。 アノテーションはorg.springframework.data.cassandra.mappingパッケージにあるが、 代表的なアノテーションの概要は以下の通りである。
| アノテーション | 設定 | 概要 |
|---|---|---|
| @Table | クラス | エンティティクラスとマッピングする物理テーブル名を指定する。 |
| @PrimaryKeyClass | クラス | 複合主キーで使用されるカラムを表現するクラス |
| @Id | フィールド | IDとして表現するフィールドに付与する。 |
| @PrimaryKey | フィールド | @Idと機能は同じで、カラム名を指定可能である。 |
| @PrimaryKeyColumn | フィールド | パーティションカラム、クラスタカラムを指定できるプライマリキーカラム |
| @Column | フィールド | フィールドとデータベースのカラム名のマッピングを定義する。 |
| @Transient | フィールド | 永続化しないエンティティクラス、マップドスーパークラス、 または組み込みクラスのフィールドであることを示す。 |
| @CassandraType | フィールド | Cassandraのデータ型を指定する際に利用する。 |
| @UserDefinedType | クラス | ユーザ定義型に付与する際に利用する。 |
以降、上記のアノテーションを付与したサンプルを幾つか記載する。
ユーザエンティティを表現するUserクラスにテーブル名を指定した@Tableアノテーションを設定する。各フィールドには各カラム名を指定した@Columnアノテーションを付与する。
package org.debugroom.sample.cassandra.pattern1.domain.entity;
import java.util.Date;
import java.util.List;
import org.springframework.data.annotation.Transient;
import org.springframework.data.cassandra.mapping.CassandraType;
import org.springframework.data.cassandra.mapping.Column;
import org.springframework.data.cassandra.mapping.PrimaryKey;
import org.springframework.data.cassandra.mapping.Table;
import com.datastax.driver.core.DataType.Name;
import com.datastax.driver.core.UDTValue;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
@AllArgsConstructor
@Data
@Builder
@Table("users")
public class User{
public User(){
}
@PrimaryKey("user_id")
private Long userId;
@Column("user_name")
private String userName;
@Column("is_enabled")
private boolean isEnabled;
@Column("is_locked")
private boolean isLocked;
@Column("is_admin")
private boolean isAdmin;
@Column("ver")
private int ver;
@Column("last_updated_date")
private Date lastUpdatedDate;
@CassandraType(type = Name.UDT, userTypeName="addressofuser")
private UDTValue address;
@Transient
List<Credential> credentials;
@Transient
List<Email> emails;
@Column("groups")
List<GroupOfUser> groups;
}
Note
@AllArgsConstructorや@Builder、@Dataアノテーションはコードを簡略化して記述するためのLombokアノテーションである。
Note
Spring Data Cassandraでは、ユーザ定義型を使用する場合、直接ユーザ定義型のクラスをプロパティとして定義する方法と、UDTValueクラスを使用する2通りの定義の仕方があるが、UDTValueを使用する場合、AP起動前に事前にCREATE TYPE文で、ユーザ定義型を定義しておく必要がある。直接クラスをプロパティに指定した場合は、設定ファイルにおいて、SchemaActionでCREATE、RECREATE等指定しておくと、AP起動時に、自動でCREATE TYPE文が発行される。
同様に、各テーブルと対応するクラスを各々作成する。なお、テーブルの構成や非正規化のポイントについてはユースケースごとの説明のセクションで後述するが、以下は、ユーザ定義型を使用したAddressOfUserクラスでの例である。クラスに@UserDefinedTypeを付与する。
package org.debugroom.sample.cassandra.pattern1.domain.entity;
import java.util.Date;
import org.springframework.data.cassandra.mapping.CassandraType;
import org.springframework.data.cassandra.mapping.Column;
import org.springframework.data.cassandra.mapping.UserDefinedType;
import com.datastax.driver.core.DataType.Name;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
@AllArgsConstructor
@Builder
@Data
@UserDefinedType
public class AddressOfUser {
@Column("zip_cd")
private String zipCd;
@Column("address")
private String address;
@Column("ver")
private int ver;
@Column("last_updated_date")
private Date lastUpdatedDate;
}
Repositoryクラスの作成¶
作成したエンティティクラスのRepositoryクラスを作成する。Spring Data JPA同様 、org.springframework.data.repository.CrudRepositoryを継承したインターフェースを作成し、型パラメータに作成したエンティティクラスとキーとなるデータ型を指定することで、基本的なCRUD操作を実行するメソッドをもつDAOが作成できる。以下は、Userエンティティクラスに対するRepositoryクラスの例である。
package org.debugroom.sample.cassandra.pattern1.domain.repository;
import java.util.List;
import org.springframework.data.repository.CrudRepository;
import org.debugroom.sample.cassandra.pattern1.domain.entity.User;
public interface UserRepository extends CrudRepository<User, Long>, UserRepositoryCustom{
}
Note
Spring Data JPA同様、命名規約に従って、メソッド名を定義すること により自動でCQLが生成される。
Note
Spring Data JPA同様、カスタムメソッドを作成することも可能である(「特定の郵便番号を持たないユーザ一覧を取得する」にて後述)。
Note
“NOT IN”や”GROUP BY”などCQLではサポートされない構文を含めたメソッドを定義できるが、実行すると当然エラーとなる。
Serviceクラスの作成¶
ユースケースに応じて、インターフェースを作成する。なお、Spring Data JPAの例で内容が重複しているユースケースは除外した。
- 全てのユーザを検索する。
→ getUsers() - 全ての住所を検索する。
→ getAddresses() - 全てのメールアドレスを検索する。
→ getEmails() - 全てのグループを検索する。
→ getGroups() - 特定のユーザを検索する。
→ getUser(Long userId) - 特定のユーザのアドレスを検索する。
→ getAddress(Long userId) - 特定のユーザがもつEmailアドレスを検索する。
→ getEmails(Long userId) - 指定したグループ名を元にグループを検索する。
→ getGroups(String groupName) - 特定の郵便番号を持つユーザ一覧を取得する。
→ getUsers(String zipCd) - 特定の郵便番号を持たないユーザ一覧を取得する
→ getNotUsers(String zipCd) - 指定されたユーザの住所を追加する。
→ addAddress(Long userId, String zipCd, String address) - 指定されたユーザの住所を更新する。
→ updateAddress(Long userId, String zipCd, String address) - 指定されたユーザの住所を削除する。
→ deleteAddress(Long userId) - 特定のメールアドレスを持つユーザを検索する。
→ getUserByEmail(String email) - 指定されたユーザのメールアドレスを追加する。
→ addEmail(Long userId, String email) - 指定されたユーザをメールアドレスを含めて追加する。
→ addUserWithEmail(Long userId, String userName, String email) - 指定されたユーザのメールアドレスを更新する。
→ updateEmail(Long userId, String email, String newEmail) - 指定されたユーザのメールアドレスを1件削除する。
→ deleteEmail(Long userId, String email) - 指定されたユーザのメールアドレスを全件削除する。
→ deleteEmails(Long userId) - 指定したユーザが属するグループの一覧を取得する。
→ getGroups(Long userId) - 指定したグループに所属する全てのユーザ一覧を取得する。
→ getUsersByGroupId(Long groupId) - 指定したグループに所属しない全てのユーザ一覧を取得する。
→ getNotUsersByGroupId(Long groupId) - 指定したユーザを指定したグループに追加する。
→ addUserToGroup(Long userId, Long groupId) - 指定したユーザをグループから除外する。
→ deleteUserFromGroup(Long userId, Long groupId) - 指定したグループを削除し、ユーザが所属するグループの情報を更新する。
→ deleteGroup(Long groupId) - 指定されたユーザを削除し、グループのユーザ一覧を更新する。
→ deleteUser(Long userId)
以下の通りのServiceインターフェースを作成し、各パターンに応じたService実装クラスを作成する。
package org.debugroom.sample.cassandra.domain.service;
import java.util.List;
public interface SampleService<U, A, E, G> {
public List<U> getUsers();
public List<A> getAddresses();
public List<E> getEmails();
public List<G> getGroups();
public U getUser(Long userId);
public U getUser(String loginId);
public A getAddress(Long userId);
public List<E> getEmails(Long userId);
public List<G> getGroups(String groupName);
public List<U> getUsers(String zipCd);
public List<U> getNotUsers(String zipCd);
public U addAddress(Long userId, String zipCd, String address);
public U updateAddress(Long userId, String zipCd, String address);
public U deleteAddress(Long userId);
public U getUserByEmail(String email);
public U addEmail(Long userId, String email);
public U addUserWithEmail(Long userId, String userName, String email);
public U updateEmail(Long userId, String email, String newEmail);
public U deleteEmail(Long userId, String email);
public U deleteEmails(Long userId);
public List<G> getGroups(Long userId);
public List<U> getUsersByGroupId(Long groupId);
public List<U> getNotUsersByGroupId(Long groupId);
public G addUserToGroup(Long userId, Long groupId);
public G deleteUserFromGroup(Long userId, Long groupId);
public G deleteGroup(Long groupId);
public U deleteUser(Long userId);
}
以降、各々のユースケースにおいて、サービスの実装を含め、詳述する。
パターン1(非正規化モデル)を中心としたデータモデル¶
データのモデリングによって、実装のパターンは異なる。まず最初にデータモデルの非正規化を中心としたパターンについて実装方法を考察する。 本サンプルでは、以下の構成をパターン1として実装例を記述する。
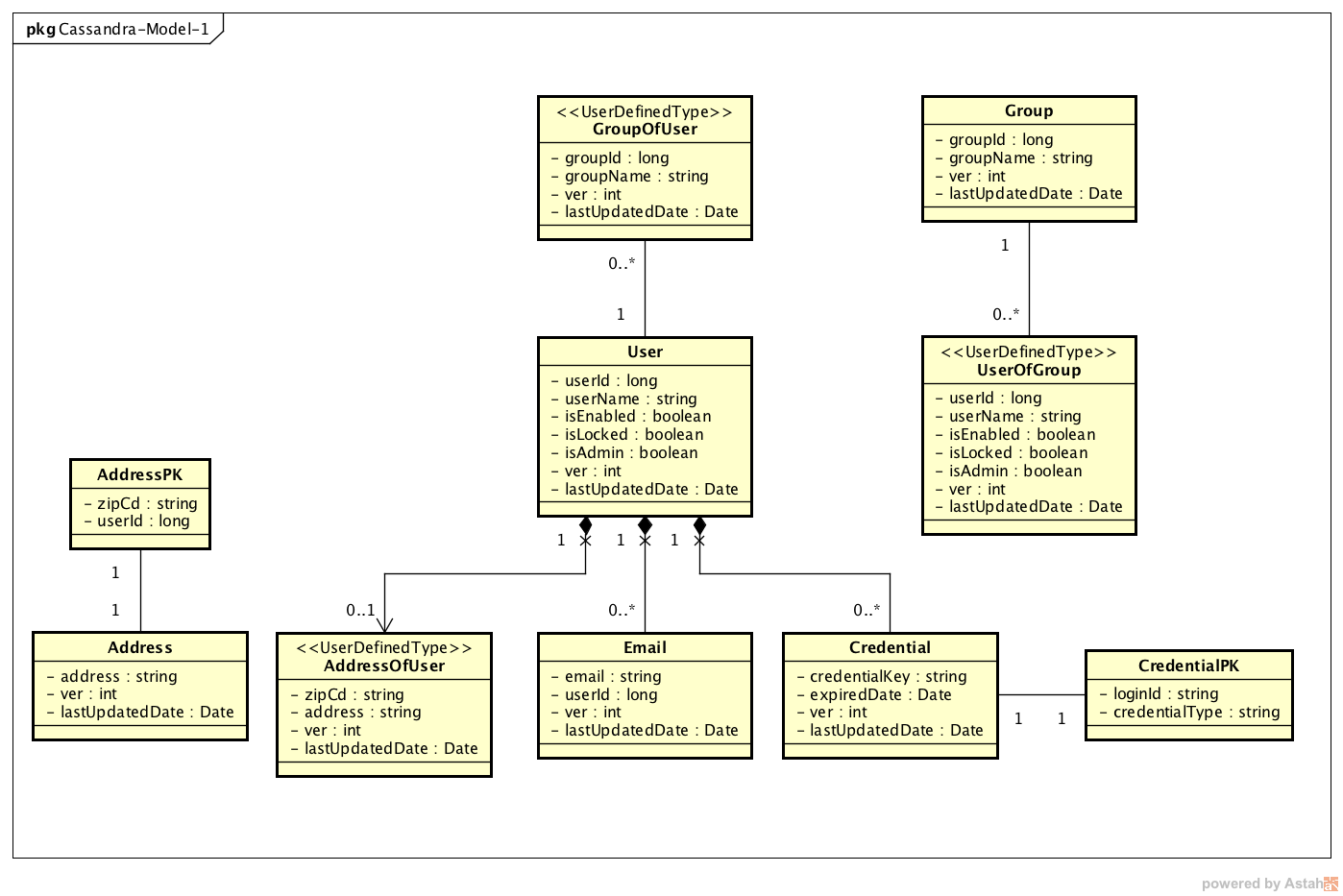
なお、上記のテーブル構成は以下のCQLによって構成されるものと同等である。
CREATE TYPE sample.addressofuser (
address text,
last_updated_date timestamp,
ver int,
zip_cd text
);
CREATE TYPE sample.groupofuser (
group_id bigint,
group_name text,
last_updated_date timestamp,
ver int
);
CREATE TYPE sample.userofgroup (
is_admin boolean,
is_enabled boolean,
is_locked boolean,
last_updated_date timestamp,
user_id bigint,
user_name text,
ver int
);
CREATE TABLE sample.credential (
login_id text,
credential_type text,
credential_key text,
expired_date timestamp,
last_updated_date timestamp,
user_id bigint,
ver int,
PRIMARY KEY ((login_id, credential_type))
);
CREATE TABLE sample.users (
user_id bigint PRIMARY KEY,
address frozen<addressofuser>,
groups list<frozen<groupofuser>>,
is_admin boolean,
is_enabled boolean,
is_locked boolean,
last_updated_date timestamp,
user_name text,
ver int
);
CREATE TABLE sample.group (
group_id bigint PRIMARY KEY,
group_name text,
last_updated_date timestamp,
users list<frozen<userofgroup>>,
ver int
);
CREATE TABLE sample.email (
email text PRIMARY KEY,
last_updated_date timestamp,
user_id bigint,
ver int
);
CREATE TABLE sample.address (
zip_cd text,
user_id bigint,
address text,
last_updated_date timestamp,
ver int,
PRIMARY KEY (zip_cd, user_id)
);
全てのユーザを検索する¶
Service実装クラスでは、CrudRepositoryインターフェースを継承したインターフェースのメソッドを呼び出せばよい。 Userテーブルのすべてのデータを検索する場合は、UserRepository.findAll()を使用する。
package org.debugroom.sample.cassandra.pattern1.domain.service;
// omit import statement.
@Slf4j
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
UserRepository userRepository;
// omit
@Override
public List<User> getUsers() {
return (List<User>)userRepository.findAll();
}
全ての住所を検索する¶
住所の全てのデータを一括検索する場合にはAddressエンティティクラスを作成し、テーブルを構成する必要がある。 Service実装クラスでは、CrudRepositoryインターフェースを継承したインターフェースのメソッドを呼び出せばよい。 Addressテーブルのすべてのデータを検索する場合は、AddressRepository.findAll()を使用する。
package org.debugroom.sample.cassandra.pattern1.domain.entity;
import java.util.Date;
import org.springframework.data.cassandra.mapping.Column;
import org.springframework.data.cassandra.mapping.PrimaryKey;
import org.springframework.data.cassandra.mapping.Table;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
@AllArgsConstructor
@Builder
@Data
@Table("address")
public class Address {
// constructor needs for avoiding repository instantiation error
public Address(){
}
@PrimaryKey("addresspk")
private AddressPK addresspk;
@Column("address")
private String address;
@Column("ver")
private int ver;
@Column("last_updated_date")
private Date lastUpdatedDate;
}
Note
エンティティクラスは引数なしのコンストラクタが必要なことに注意。それがないと、AP起動時にレポジトリクラスをインスタンス化する際にエラーが発生する。なお、プライマリーキークラスも同様だが、起動時にorg.springframework.data.mapping.PropertyReferenceException: No property ”property” found for type “class” となるので注意すること。
package org.debugroom.sample.cassandra.pattern1.domain.repository;
import org.debugroom.sample.cassandra.pattern1.domain.entity.Address;
import org.debugroom.sample.cassandra.pattern1.domain.entity.AddressPK;
import org.springframework.data.repository.CrudRepository;
public interface AddressRepository extends CrudRepository<Address, AddressPK>{
}
Note
通常、1つのユーザが1つの住所を保持できるようにする(リレーショナルデータモデルでいうところの1対1の関係の)場合、ユニークなIDか、ユーザIDをキーにして実現するが、ここではAddressPKというクラスを作成して主キーにしている。理由はセクション「特定の郵便番号をもつユーザを検索する」にて後述する。
package org.debugroom.sample.cassandra.pattern1.domain.service;
// omit import statement.
@Slf4j
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
AddressRepository addressRepository;
// omit
@Override
public List<Address> getAddresses() {
return (List<Address>)addressRepository.findAll();
}
全てのメールアドレスを検索する¶
全てのデータを一括検索する場合にはEmailエンティティクラスを作成し、テーブルを構成する必要がある。 Service実装クラスでは、CrudRepositoryインターフェースを継承したインターフェースのメソッドを呼び出せばよい。 Emailテーブルのすべてのデータを検索する場合は、EmailRepository.findAll()を使用する。
package org.debugroom.sample.cassandra.pattern1.domain.entity;
import org.springframework.data.cassandra.mapping.PrimaryKey;
import org.springframework.data.cassandra.mapping.Table;
import java.util.Date;
import org.springframework.data.cassandra.mapping.Column;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
@AllArgsConstructor
@Builder
@Data
@Table("email")
public class Email {
public Email(){
}
@PrimaryKey("email")
private String email;
@Column("user_id")
private Long userId;
@Column("ver")
private int ver;
@Column("last_updated_date")
private Date lastUpdatedDate;
}
Note
通常、1つのユーザが複数のメールアドレスを保持できるようにする(リレーショナルデータモデルでいうところの1対多の関係の)場合、ユニークなIDか、ユーザIDと番号などの複合主キーにして実現するが、ここではユニークな値となるメールアドレスそのものを主キーにしている。理由はセクション「特定のユーザがもつEmailアドレスを検索する」にて後述する。
package org.debugroom.sample.cassandra.pattern1.domain.repository;
import org.springframework.data.repository.CrudRepository;
import org.debugroom.sample.cassandra.pattern1.domain.entity.Email;
public interface EmailRepository extends CrudRepository<Email, String>{
}
package org.debugroom.sample.cassandra.pattern1.domain.service;
// omit import statement.
@Slf4j
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
EmailRepository emailRepository;
// omit
@Override
public List<Email> getEmails() {
return (List<Email>) emailRepository.findAll();
}
全てのグループを検索する¶
全てのデータを一括検索する場合にはGroupエンティティクラスを作成し、テーブルを構成する必要がある。 Service実装クラスでは、CrudRepositoryインターフェースを継承したインターフェースのメソッドを呼び出せばよい。 Groupテーブルのすべてのデータを検索する場合は、GroupRepository.findAll()を使用する。
package org.debugroom.sample.cassandra.pattern1.domain.entity;
import java.util.Date;
import java.util.List;
import org.springframework.data.cassandra.mapping.Column;
import org.springframework.data.cassandra.mapping.PrimaryKey;
import org.springframework.data.cassandra.mapping.Table;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
@AllArgsConstructor
@Builder
@Data
@Table("group")
public class Group {
public Group(){
}
@PrimaryKey("group_id")
private Long groupId;
@Column("group_name")
private String groupName;
@Column("ver")
private int ver;
@Column("last_updated_date")
private Date lastUpdatedDate;
}
package org.debugroom.sample.cassandra.pattern1.domain.repository;
import org.debugroom.sample.cassandra.pattern1.domain.entity.Group;
import org.springframework.data.repository.CrudRepository;
public interface GroupRepository extends CrudRepository<Group, Long>{
}
package org.debugroom.sample.cassandra.pattern1.domain.service;
// omit import statement.
@Slf4j
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
GroupRepository groupRepository;
// omit
@Override
public List<Group> getGroups() {
return (List<Group>) groupRepository.findAll();
}
特定のユーザを検索する¶
ユーザデータをプライマリーキーuserIdを使用して検索する場合には、Service実装クラスでは、CrudRepositoryインターフェースを継承したインターフェースのメソッドを呼び出せばよい。UserRepository.findOne(Long userId)を使用する。
package org.debugroom.sample.cassandra.pattern1.domain.service;
// omit import statement.
@Slf4j
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
UserRepository userRepository;
// omit
@Override
public User getUser(Long userId) {
return userRepository.findOne(userId);
}
特定のユーザのアドレスを検索する¶
特定のユーザIDをキーに住所を検索する場合、いくつか方法がある。他にどのような住所検索のクエリが必要かによって、適切な実装方法は異なる。まず、ここでは、エンティティUserにユーザ定義型AddressOfUserを定義して、ユーザテーブルから非正規化した住所データを取得する例を記載する。
package org.debugroom.sample.cassandra.pattern1.domain.entity;
// omit import statement
@AllArgsConstructor
@Data
@Builder
@Table("users")
public class User{
public User(){
}
@PrimaryKey("user_id")
private Long userId;
// omit
@CassandraType(type = Name.UDT, userTypeName="addressofuser")
private UDTValue address; // ユーザ定義型AddressOfUserを使用してデータを非正規化する。
}
当然Addressテーブルにも同じ住所のデータはあるが、このように非正規化している理由は、後述するユースケース「特定の郵便番号を持つユーザ一覧を取得する」でも示すように、郵便番号をAddressテーブルの検索条件のキーに持たせる必要があり、Addressエンティティではプライマリキーとして、郵便番号とユーザIDを複合主キーとしたAddressPKを作成しているため、Addressテーブルは、userId単体ではデフォルトそのままでは検索キーとして使用できないためである。
package org.debugroom.sample.cassandra.pattern1.domain.entity;
@AllArgsConstructor
@Builder
@Data
@Table("address")
public class Address {
public Address(){
}
@PrimaryKey("addresspk")
private AddressPK addresspk; //Addressテーブルの検索にはaddressPKのzipCdが必要。
@Column("address")
private String address;
@Column("ver")
private int ver;
@Column("last_updated_date")
private Date lastUpdatedDate;
}
package org.debugroom.sample.cassandra.pattern1.domain.entity;
import java.io.Serializable;
import org.springframework.cassandra.core.PrimaryKeyType;
import org.springframework.data.cassandra.mapping.PrimaryKeyClass;
import org.springframework.data.cassandra.mapping.PrimaryKeyColumn;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
@AllArgsConstructor
@Builder
@Data
@PrimaryKeyClass
public class AddressPK implements Serializable{
public AddressPK(){}
private static final long serialVersionUID = -828112214783052932L;
@PrimaryKeyColumn(name = "zip_cd", ordinal = 0, type = PrimaryKeyType.PARTITIONED)
private String zipCd; // zipCdはパーティションキーで指定しているので必須
@PrimaryKeyColumn(name = "user_id", ordinal = 1, type = PrimaryKeyType.CLUSTERED)
private Long userId; // userIdはクラスタカラムとして指定しているので必須ではない
}
Note
AddressPKクラスにおいて、クラスタカラムとして定義しているuserIdを単体の検索キーとして利用するには、セカンダリインデックスを作成すれば可能であるが、DataStax社の提供するCassandraのドキュメント ではカーディナリティの高い(バラエティが多い)データで、セカンダリインデックスを作るのは推奨していない。カーディナリティの高いデータに対してはマテリアライズドビューの作成を推奨しているが、いずれにせよパーティションキーである郵便番号が必要になる。
Serviceの実装クラスでは、Userテーブルから非正規化した住所データをcom.datastax.driver.core.UDTValueの形式で取得している。 これをAddressクラスにデータを移した返却している。
package org.debugroom.sample.cassandra.pattern1.domain.service;
import com.datastax.driver.core.UDTValue
// omit other import statement.
@Slf4j
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
UserRepository userRepository;
// omit
@Override
public Address getAddress(Long userId) {
UDTValue udtValue = userRepository.findOne(userId).getAddress();
if(udtValue == null){
return null;
}
return Address.builder()
.addresspk(AddressPK.builder()
.userId(userId)
.zipCd(udtValue.getString("zip_cd"))
.build())
.address(udtValue.getString("address"))
.ver(udtValue.getInt("ver"))
.lastUpdatedDate(udtValue.getTimestamp("last_updated_date"))
.build();
}
Warning
com.datastax.driver.core.UDTValueは今回サンプルとして使用方法を記述しているが、特定のベンダのパッケージにServiceクラスが依存してしまうのであまり使用しない方が良い。Spring Data Cassandraでは、ユーザ定義型はUDTValueクラスを使用せずとも直接@UserDefinedTypeアノテーションが付与されたクラスを変数宣言すると使用可能なのでそちらの利用を推奨。
特定のユーザがもつEmailアドレスを検索する¶
Emailテーブルでは、Emailがプライマリキーであるため、CQLのwhere句の条件にuserIdは指定できない。
package org.debugroom.sample.cassandra.pattern1.domain.entity;
// omit import statement.
@AllArgsConstructor
@Builder
@Data
@Table("email")
public class Email {
public Email(){
}
@PrimaryKey("email")
private String email; // <---通常ではプライマリキーしかwhere句に指定できない
@Column("user_id")
private Long userId; // <---セカンダリインデックスを指定等すれば、検索キーとしては利用可能。
@Column("ver")
private int ver;
@Column("last_updated_date")
private Date lastUpdatedDate;
}
特定のユーザがもつEmailアドレスを検索する場合、こちらも「特定のユーザのアドレスを検索する」と同様、ユーザテーブルに非正規化されたEmailデータを持たせるのが簡易ではあるが、こちらのユースケースでは、逆に非正規化せず、プライマリーキー以外の項目をwhere条件で指定して検索する方法で実装する。基本的には、セカンダリインデックスを作成するか、EmailRepositoryクラスにCQLを定義し、オプションでallow filteringオプションを指定するか、マテリアライズドビューを作成すれば可能である。ここでは、EmailRepositoryインターフェースにfindByUserIdメソッドを定義し、allow filteringオプションを付与した例を有効化している。
package org.debugroom.sample.cassandra.pattern1.domain.repository;
import java.util.List;
import org.springframework.data.cassandra.repository.Query;
import org.springframework.data.repository.CrudRepository;
import org.debugroom.sample.cassandra.pattern1.domain.entity.Email;
public interface EmailRepository extends CrudRepository<Email, String>{
// Use secondary index or materialized view depending on data cardinality.
// (Not recommend) 1. Create secondary index
// "create index on sample.email (user_id);"
// @Query("select * from email where user_id = ?0")
// (Not recommend) 2. Add allow filtering option to cql.
@Query("select * from email where user_id = ?0 allow filtering")
// (Recommend) 3. Use materialized view
// "create materialized view email_by_user_id as select email, user_id, ver, last_updated_date from email where user_id is not null and email is not null primary key(user_id, email);"
//@Query("select * from email_by_user_id where user_id = ?0")
public List<Email> findByUserId(Long userId);
}
Warning
userIdはユニークな値なので、本来一番推奨される方法はマテリアライズドビューを使用する方法である。
Service実装クラスからは、定義したメソッドEmailRepository.findByUserId()を実行すれば良い。
package org.debugroom.sample.cassandra.pattern1.domain.service;
import com.datastax.driver.core.UDTValue
// omit other import statement.
@Slf4j
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
EmailRepository emailRepository;
// omit
@Override
public List<Email> getEmails(Long userId) {
return emailRepository.findByUserId(userId);
}
指定したグループ名を元にグループを検索する¶
Groupテーブルでは、groupIdがプライマリキーであるため、CQLのwhere句の条件にgroupNameは指定できない。
package org.debugroom.sample.cassandra.pattern1.domain.entity;
// omit import statement.
@AllArgsConstructor
@Builder
@Data
@Table("group")
public class Group {
public Group(){
}
@PrimaryKey("group_id")
private Long groupId; // <-- where句に条件指定ができる
@Column("group_name")
private String groupName; // <-- where句に条件指定ができない
// omit
}
こちらも、「特定のユーザがもつEmailアドレスを検索する 」と同様、GroupRepositoryインターフェースにfindByGroupNameメソッドを定義し、allow filteringオプションを付与した例を有効化している。
package org.debugroom.sample.cassandra.pattern1.domain.repository;
import java.util.List;
import org.debugroom.sample.cassandra.pattern1.domain.entity.Group;
import org.springframework.data.cassandra.repository.Query;
import org.springframework.data.repository.CrudRepository;
public interface GroupRepository extends CrudRepository<Group, Long>{
// Use query adding allow filtering option or secondary index or materialized view.
@Query("select * from group where group_name = ?0 allow filtering")
public List<Group> findByGroupName(String groupName);
}
Todo
検索キーとなる項目のカーディナリティに応じて、適切な方法を選択するために、目安となるベンチマークを測定する。
特定の郵便番号を持つユーザ一覧を取得する¶
リレーショナルモデルでは1対1関連として扱いたいUserとAddressエンティティの関係であるが、特定の項目をキーにした検索が必要なユースケースでは、その項目をプライマリキーにしておくことで高速な検索が見込める。ここでは、郵便番号と、ユーザIDをプライマリキーをAddressPKクラスとして定義した例で実装する。
package org.debugroom.sample.cassandra.pattern1.domain.entity;
// omit import statement.
@AllArgsConstructor
@Builder
@Data
@Table("address")
public class Address {
@PrimaryKey("addresspk")
private AddressPK addresspk; //<-プライマリキークラスを作成。
// omit.
}
package org.debugroom.sample.cassandra.pattern1.domain.entity;
import java.io.Serializable;
import org.springframework.cassandra.core.PrimaryKeyType;
import org.springframework.data.cassandra.mapping.PrimaryKeyClass;
import org.springframework.data.cassandra.mapping.PrimaryKeyColumn;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
@AllArgsConstructor
@Builder
@Data
@PrimaryKeyClass
public class AddressPK implements Serializable{
public AddressPK(){}
private static final long serialVersionUID = -828112214783052932L;
@PrimaryKeyColumn(name = "zip_cd", ordinal = 0, type = PrimaryKeyType.PARTITIONED)
private String zipCd; // パーティションキーとして定義
@PrimaryKeyColumn(name = "user_id", ordinal = 1, type = PrimaryKeyType.CLUSTERED)
private Long userId; // クラスタカラムキーとして定義
}
Warning
パーティションキーはどのノードにデータを配置するかを決定する重要なキーである。 パーティションキーの指定なしに検索を行うと、どのノードにデータが配置されているかをトレースせねばならず、 ノードが増えるごとに線形的に検索速度は低下する。
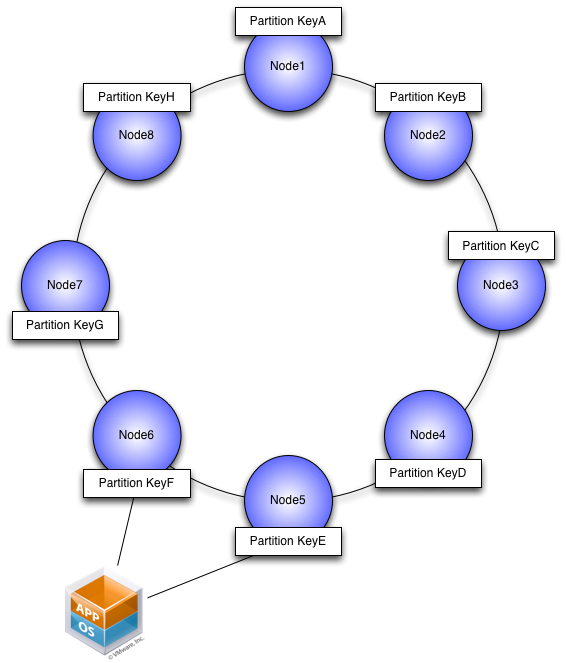
クラスタカラムキーはパーティションに格納されたデータのキーとなる項目である。
Serviceクラスの実装では、まずパーティションキーであるzipCdを指定して、対象のAddressオブジェクトのリストを取得したのち、AddressオブジェクトのuserIdのリストを作って、IN句を使ってユーザデータを検索する。zipCdをキーにアドレスリストを取得するためにAddressRepositoryにfindByAddresspkZipCdメソッドを定義する。
package org.debugroom.sample.cassandra.pattern1.domain.repository;
import org.debugroom.sample.cassandra.pattern1.domain.entity.Address;
import org.debugroom.sample.cassandra.pattern1.domain.entity.AddressPK;
import org.springframework.data.repository.CrudRepository;
public interface AddressRepository extends CrudRepository<Address, AddressPK>{
public List<Address> findByAddresspkZipCd(String zipCd);
}
Note
メソッドの命名規約により、Spring Data Cassandraが、findByAddresspxZipCdでAddressPKクラスのzipCdをキーにCQLを組み立てる。なお、ネストされたクラスはキャメルケースによりプロパティ名を推定するが、英大文字小文字の区別を明確化するために@PraimaryKeyで変数名を明確に定義しておくこと。
また、UserRepositoryインターフェースにIN句を使用したCQLを実行するよう、findByUserIdIn(List<Long> userIds)メソッドを作成する。
package org.debugroom.sample.cassandra.pattern1.domain.repository;
import java.util.List;
import org.springframework.data.repository.CrudRepository;
import org.debugroom.sample.cassandra.pattern1.domain.entity.User;
public interface UserRepository extends CrudRepository<User, Long>, UserRepositoryCustom{
public List<User> findByUserIdIn(List<Long> userIds);
}
Service実装クラスでは、
package org.debugroom.sample.cassandra.pattern1.domain.service;
import com.datastax.driver.core.UDTValue
// omit other import statement.
@Slf4j
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
UserRepository userRepository;
@Autowired
AddressRepository addressRepository;
// omit
@Override
public List<User> getUsers(String zipCd) {
List<Address> addresses = addressRepository.findByAddresspkZipCd(zipCd);
List<Long> userIds = new ArrayList<Long>();
for(Address address : addresses){
userIds.add(address.getAddresspk().getUserId());
}
return userRepository.findByUserIdIn(userIds);
}
Todo
IN句の実行速度が不明のため、マルチノードでデータを分散した場合の実行速度を計測して評価すること。
特定の郵便番号を持たないユーザ一覧を取得する¶
特定の郵便番号を持たないユーザの一覧だと、「特定の郵便番号を持つユーザ一覧を取得する」場合の論理否定であるが、CQLではNOT IN句をサポートしていない。そのため、別の方法で全体のユーザから特定の郵便番号をもつユーザを除外することで、持たないユーザ一覧を作成する。 1件ずつ対象のユーザをループでチェックするとデータが大きくなった場合、指数関数的に増加するため、Map型でユーザの一覧を取得し、特定の郵便番号を持つユーザのリストから除外する方法で実装する。
package org.debugroom.sample.cassandra.pattern1.domain.service;
import com.datastax.driver.core.UDTValue
// omit other import statement.
@Slf4j
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
UserRepository userRepository;
@Autowired
AddressRepository addressRepository;
// omit
@Override
public List<User> getNotUsers(String zipCd) {
/* Not_In statement is no-supported for cassandra.
List<Address> addresses = addressRepository.findByAddresspkZipCd(zipCd);
List<Long> userIds = new ArrayList<Long>();
for(Address address : addresses){
userIds.add(address.getAddresspk().getUserId());
}
return userRepository.findByUserIdNotIn(userIds);
*/
List<Address> addresses = addressRepository.findByAddresspkZipCd(zipCd);
Map<Long, User> usersMap = userRepository.findAllForMap();
for(Address address : addresses){
usersMap.remove(address.getAddresspk().getUserId());
}
return new ArrayList<User>(usersMap.values());
}
検索結果をMap型で返却するメソッドはSpring Dataでは標準ではサポートされていないため、カスタムレポジトリクラスを作成し、Map型で返却するよう拡張する。なお、データのマッピングはorg.springframework.cassandra.core.ResultSetExtractorを利用する。まず、Repositoryを拡張するためのカスタムインターフェースを作成する。
package org.debugroom.sample.cassandra.pattern1.domain.repository;
import java.util.Map;
import org.debugroom.sample.cassandra.pattern1.domain.entity.User;
public interface UserRepositoryCustom {
public Map<Long, User> findAllForMap();
}
カスタムインターフェースをUserRepositoryクラスに継承させる。
package org.debugroom.sample.cassandra.pattern1.domain.repository;
import java.util.List;
import org.springframework.data.repository.CrudRepository;
import org.debugroom.sample.cassandra.pattern1.domain.entity.User;
public interface UserRepository extends CrudRepository<User, Long>, UserRepositoryCustom{
public List<User> findByUserIdIn(List<Long> userIds);
public List<User> findByUserIdNotIn(List<Long> userIds);
}
カスタムインターフェースの実装クラスを作成する。
package org.debugroom.sample.cassandra.pattern1.domain.repository.impl;
import java.util.Map;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.data.cassandra.core.CassandraOperations;
import org.springframework.data.repository.NoRepositoryBean;
import com.datastax.driver.core.querybuilder.QueryBuilder;
import com.datastax.driver.core.querybuilder.Select;
import org.debugroom.sample.cassandra.pattern1.domain.entity.User;
import org.debugroom.sample.cassandra.pattern1.domain.repository.UserRepositoryCustom;
@NoRepositoryBean
public class UserRepositoryImpl implements UserRepositoryCustom{
@Autowired
@Qualifier("cassandraTemplate")
CassandraOperations cassandraOperations;
@Override
public Map<Long, User> findAllForMap() {
Select select = QueryBuilder.select().from("users");
return cassandraOperations.query(select, new UserMapExtractor());
}
Warning
Repositoryインターフェースと同一のパッケージに配置していると、メソッド名命名規約のチェックが発生して、(ここではForMapという変数がない等でエラーが発生してしまう。)自由なメソッド名を設定できなくなるため、レポジトリ実装クラスは@NoRepositoryBeanアノテーションを付与し、別パッケージに配置すること。
また、ResultSetとエンティティクラスのカラムマッピングの拡張で、ResultSetExtractorを継承したクラスを以下の通り実装する。
package org.debugroom.sample.cassandra.pattern1.domain.repository.impl;
import java.util.Map;
import java.util.List;
import java.util.ArrayList;
import java.util.HashMap;
import org.springframework.cassandra.core.ResultSetExtractor;
import org.springframework.dao.DataAccessException;
import com.datastax.driver.core.ResultSet;
import com.datastax.driver.core.Row;
import com.datastax.driver.core.UDTValue;
import com.datastax.driver.core.exceptions.DriverException;
import org.debugroom.sample.cassandra.pattern1.domain.entity.GroupOfUser;
import org.debugroom.sample.cassandra.pattern1.domain.entity.User;
public class UserMapExtractor implements ResultSetExtractor<Map<Long, User>> {
@Override
public Map<Long, User> extractData(ResultSet resultSet)
throws DriverException, DataAccessException {
Map<Long, User> userMap = new HashMap<Long, User>();
while(resultSet.iterator().hasNext()){
Row row = resultSet.one();
List<GroupOfUser> groupOfUsers = new ArrayList<GroupOfUser>();
User user = User.builder()
.userId(row.getLong("user_id"))
.userName(row.getString("user_name"))
.isEnabled(row.getBool("is_enabled"))
.isLocked(row.getBool("is_locked"))
.isAdmin(row.getBool("is_admin"))
.address(row.getUDTValue("address"))
// .groups(row.getList("groups", GroupOfUser.class))
.groups(groupOfUsers)
.ver(row.getInt("ver"))
.lastUpdatedDate(row.getTimestamp("last_updated_date"))
.build();
@SuppressWarnings("unchecked")
List<UDTValue> groups = (List<UDTValue>) row.getObject("groups");
for(UDTValue udtValue : groups){
GroupOfUser groupOfUser = new GroupOfUser();
groupOfUser.setGroupId(udtValue.getLong("group_id"));
groupOfUser.setGroupName(udtValue.getString("group_name"));
groupOfUser.setVer(udtValue.getInt("ver"));
groupOfUser.setLastUpdatedDate(udtValue.getTimestamp("last_updated_date"));
groupOfUsers.add(groupOfUser);
}
userMap.put(row.getLong("user_id"), user);
}
return userMap;
}
}
Note
ユーザ定義型のListオブジェクトのマッピングがRow.getList()メソッドではうまく動作しなかったため、row.getObject()にてリスト型データを取得し、マッピングし直している。
指定されたユーザの住所を追加する¶
指定されたユーザの住所データを追加する場合は、Repositoryクラスのsaveメソッドを利用すれば良いが、本サンプルでは郵便番号検索や、住所全件検索のために住所データをAddressテーブルと、UserテーブルのAddressOfUserプロパティに非正規化している。そのため、Service実装クラスでは、2回データの追加を行うことになる。
package org.debugroom.sample.cassandra.pattern1.domain.service;
import com.datastax.driver.core.UDTValue
// omit other import statement.
@Slf4j
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
UserRepository userRepository;
@Autowired
AddressRepository addressRepository;
// omit
@Override
public User addAddress(Long userId, String zipCd, String address) {
// Add data to Address Table
Address saveAddress = Address.builder()
.addresspk(AddressPK.builder()
.userId(userId)
.zipCd(zipCd)
.build())
.address(address)
.ver(0)
.lastUpdatedDate(new Date())
.build();
addressRepository.save(saveAddress);
// Add data to Address of User
User user = userRepository.findOne(userId);
return userRepository.addAddress(user, zipCd, address);
}
また、AddressOfUserはユーザ定義型としてUDTValueを使用しているので、カスタムレポジトリに追加で実装を行う。 UDTValueは org.springframework.data.cassandra.core.CassandraAdminOperationsからKeyspaceMetadataを取得し、UserTypeを使って生成する。
package org.debugroom.sample.cassandra.pattern1.domain.repository.impl;
import java.util.Date;
import java.util.Map;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.data.cassandra.core.CassandraAdminOperations;
import org.springframework.data.cassandra.core.CassandraOperations;
import org.springframework.data.repository.NoRepositoryBean;
import com.datastax.driver.core.KeyspaceMetadata;
import com.datastax.driver.core.UDTValue;
import com.datastax.driver.core.UserType;
import com.datastax.driver.core.querybuilder.QueryBuilder;
import com.datastax.driver.core.querybuilder.Select;
import org.debugroom.sample.cassandra.pattern1.domain.entity.User;
import org.debugroom.sample.cassandra.pattern1.domain.repository.UserRepositoryCustom;
@NoRepositoryBean
public class UserRepositoryImpl implements UserRepositoryCustom{
@Autowired
@Qualifier("cassandraTemplate")
CassandraOperations cassandraOperations;
@Autowired
@Qualifier("cassandraAdminOperations")
CassandraAdminOperations cassandraAdminOperations;
@Override
public Map<Long, User> findAllForMap() {
Select select = QueryBuilder.select().from("users");
return cassandraOperations.query(select, new UserMapExtractor());
}
@Override
public User addAddress(User user, String zipCd, String address) {
// For instantiating udtvalue object, need to use cassandraadminoperations.
KeyspaceMetadata keyspaceMetadata = cassandraAdminOperations.getKeyspaceMetadata();
UserType userTypeAddress = keyspaceMetadata.getUserType("addressofuser");
UDTValue udtValue = userTypeAddress.newValue();
udtValue.setString("zip_cd", zipCd);
udtValue.setString("address", address);
udtValue.setInt("ver", 0);
udtValue.setTimestamp("last_updated_date", new Date());
user.setAddress(udtValue);
cassandraOperations.insert(user);
return user;
}
}
なお、 org.springframework.data.cassandra.core.CassandraAdminOperationsが使用可能なよう、Bean定義を行なっておくこと。
package org.debugroom.sample.cassandra.config.infra;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.cassandra.config.SchemaAction;
import org.springframework.data.cassandra.config.java.AbstractCassandraConfiguration;
import org.springframework.data.cassandra.convert.CassandraConverter;
import org.springframework.data.cassandra.core.CassandraAdminOperations;
import org.springframework.data.cassandra.core.CassandraAdminTemplate;
import org.springframework.data.cassandra.core.CassandraTemplate;
import com.datastax.driver.core.Session;
@Configuration
public abstract class CommonCassandraConfig extends AbstractCassandraConfiguration{
@Override
public SchemaAction getSchemaAction() {
return SchemaAction.CREATE_IF_NOT_EXISTS;
}
@Bean
public CassandraTemplate cassandraTemplate(Session session){
return new CassandraTemplate(session);
}
@Bean
public CassandraAdminOperations cassandraAdminOperations() throws ClassNotFoundException{
return new CassandraAdminTemplate(session().getObject(), cassandraConverter());
}
}
指定されたユーザの住所を更新する¶
指定されたユーザの住所データを更新する場合、Cassandraでは既にキーがあるデータの追加は更新として扱われるため、Repositoryクラスのsaveメソッドを利用すれば良い。ただし、本サンプルでは郵便番号検索や、住所全件検索のために住所データをAddressテーブルと、UserテーブルのAddressOfUserプロパティに非正規化している。そのため、Service実装クラスでは、2回データの追加を行うことになる。
package org.debugroom.sample.cassandra.pattern1.domain.service;
import com.datastax.driver.core.UDTValue
// omit other import statement.
@Slf4j
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
UserRepository userRepository;
@Autowired
AddressRepository addressRepository;
// omit
@Override
public User updateAddress(Long userId, String zipCd, String address) {
Address updateAddress = addressRepository.findOne(
AddressPK.builder().userId(userId).zipCd(zipCd).build());
updateAddress.setAddress(address);
updateAddress.setVer(updateAddress.getVer()+1);
updateAddress.setLastUpdatedDate(new Date());
addressRepository.save(updateAddress);
User user = userRepository.findOne(userId);
UDTValue udtValue = user.getAddress();
udtValue.setString("address", address);
udtValue.setInt("ver", udtValue.getInt("ver")+1);
udtValue.setTimestamp("last_updated_date", new Date());
return userRepository.save(user);
}
指定されたユーザの住所を削除する¶
指定されたユーザの住所データを削除する場合、Repositoryクラスのdeleteメソッドを利用すれば良い。ただし、本サンプルでは郵便番号検索や、住所全件検索のために住所データをAddressテーブルと、UserテーブルのAddressOfUserプロパティに非正規化している。そのため、Service実装クラスでは、Addressテーブルについては、delete()メソッドで削除を行い、UserオブジェクトではNULLを設定する。
package org.debugroom.sample.cassandra.pattern1.domain.service;
// omit other import statement.
@Slf4j
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
UserRepository userRepository;
@Autowired
AddressRepository addressRepository;
// omit
@Override
public User deleteAddress(Long userId) {
List<Address> addresses = addressRepository.findByAddresspkUserId(userId);
for(Address address : addresses){
addressRepository.delete(address);
}
User user = userRepository.findOne(userId);
user.setAddress(null);
return userRepository.save(user);
}
特定のメールアドレスを持つユーザを検索する¶
特定のEmailからユーザを検索する場合、Email Tableはemailをプライマリキーとしたテーブル構造となっているので、対象のEmailを取得したのち、userIdをキーにしてUserテーブルからデータを取得する。
package org.debugroom.sample.cassandra.pattern1.domain.service;
// omit other import statement.
@Slf4j
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
UserRepository userRepository;
@Autowired
EmailRepository emailRepository;
// omit
@Override
public User getUserByEmail(String email) {
return userRepository.findOne(
emailRepository.findOne(email).getUserId());
}
指定されたユーザのメールアドレスを追加する¶
Emailを追加する場合は、EmailRepository.save()メソッドを使用すればよい。なお、UserクラスのList<Email>は@Transientを付与しているので、特に永続化はされない。あくまでView層に返す際にデータを設定しているだけである。
package org.debugroom.sample.cassandra.pattern1.domain.service;
// omit other import statement.
@Slf4j
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
UserRepository userRepository;
@Autowired
EmailRepository emailRepository;
// omit
@Override
public User addEmail(Long userId, String email) {
Email addEmail = Email.builder()
.email(email)
.userId(userId)
.ver(0)
.lastUpdatedDate(new Date())
.build();
emailRepository.save(addEmail);
List<Email> emails = emailRepository.findByUserId(userId);
emails.add(addEmail);
User user = userRepository.findOne(userId);
user.setEmails(emails);
return user;
}
指定されたユーザをメールアドレスを含めて追加する¶
ユーザデータと一緒にEmailを追加する場合も、それぞれUserRepository.save()、EmailRepository.save()メソッドを使って各々データを保存すれば良い。なお、UserクラスのList<Email>は@Transientを付与しているので、特に永続化はされない。あくまでView層に返す際にデータを設定しているだけである。
package org.debugroom.sample.cassandra.pattern1.domain.service;
// omit other import statement.
@Slf4j
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
UserRepository userRepository;
@Autowired
EmailRepository emailRepository;
// omit
@Override
public User addUserWithEmail(Long userId, String userName, String email) {
Email addEmail = Email.builder()
.email(email)
.userId(userId)
.ver(0)
.lastUpdatedDate(new Date())
.build();
emailRepository.save(addEmail);
List<Email> emails = new ArrayList<Email>();
emails.add(addEmail);
User addUser = User.builder()
.userId(userId)
.userName(userName)
.isEnabled(true)
.isLocked(false)
.isAdmin(false)
.emails(emails)
.ver(0)
.lastUpdatedDate(new Date())
.build();
return userRepository.save(addUser);
}
指定されたユーザのメールアドレスを更新する¶
Emailを更新する場合、Emailはプライマリキーであるため、そのまま更新をかけようとすると、新たなキーとしてデータが追加されてしまうため、一度データを削除して、追加を行う形でデータ更新を行う必要がある。
package org.debugroom.sample.cassandra.pattern1.domain.service;
// omit other import statement.
@Slf4j
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
UserRepository userRepository;
@Autowired
EmailRepository emailRepository;
// omit
@Override
public User updateEmail(Long userId, String email, String newEmail) {
/* Primary key updating equals new saving row.
Email updateEmail = emailRepository.findOne(email);
updateEmail.setEmail(newEmail);
emailRepository.save(updateEmail);
*/
Email deleteEmail = emailRepository.findOne(email);
emailRepository.delete(deleteEmail);
emailRepository.save(Email.builder()
.email(newEmail)
.userId(userId)
.ver(0)
.lastUpdatedDate(new Date())
.build());
User user = userRepository.findOne(userId);
user.setEmails(emailRepository.findByUserId(userId));
return user;
}
指定されたユーザのメールアドレスを1件削除する¶
Emailを削除する場合、単純に指定されたEmailオブジェクトを取得し、EmailRepository.delete()メソッドを実行すれば良い。
package org.debugroom.sample.cassandra.pattern1.domain.service;
// omit other import statement.
@Slf4j
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
UserRepository userRepository;
@Autowired
EmailRepository emailRepository;
// omit
@Override
public User deleteEmail(Long userId, String email) {
Email deleteEmail = emailRepository.findOne(email);
emailRepository.delete(deleteEmail);
User user = userRepository.findOne(userId);
user.setEmails(emailRepository.findByUserId(userId));
return user;
}
指定されたユーザのメールアドレスを全件削除する¶
Emailを全て削除する場合、ユーザIDをキーにEmailオブジェクトのリストを取得し、各データをEmailRepository.delete()メソッドを実行して各々削除すれば良い。
package org.debugroom.sample.cassandra.pattern1.domain.service;
// omit other import statement.
@Slf4j
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
UserRepository userRepository;
@Autowired
EmailRepository emailRepository;
// omit
@Override
public User deleteEmails(Long userId) {
List<Email> emails = emailRepository.findByUserId(userId);
for(Email email : emails){
emailRepository.delete(email);
}
return userRepository.findOne(userId);
}
指定したユーザが属するグループの一覧を取得する¶
指定したユーザが所属するグループを検索する場合、リレーショナルモデルでは通常多対多の関連を持ち、関連実体となるテーブル(例えば所属など)を結合して、データを取得する方法が一般的であるが、Cassandraでは結合はサポートされていない。ここでは、全件検索したGroupテーブルとは別にUserテーブルにGroupのListデータを持たせて非正規化を行う。理由は、次セクション「指定したグループに所属する全てのユーザ一覧を取得する」で説明するが、逆にGroupにもUserのデータを持たせる必要があるため、相互参照(循環参照)とならないよう、Userエンティティにユーザ定義型クラスGroupOfUserクラスを作成する。
package org.debugroom.sample.cassandra.pattern1.domain.entity;
// omit import statement.
@AllArgsConstructor
@Data
@Builder
@Table("users")
public class User{
public User(){
}
@PrimaryKey("user_id")
private Long userId;
// omit
@Column("groups")
List<GroupOfUser> groups;
}
package org.debugroom.sample.cassandra.pattern1.domain.entity;
import java.util.Date;
import java.util.List;
import org.springframework.data.cassandra.mapping.Column;
import org.springframework.data.cassandra.mapping.PrimaryKey;
import org.springframework.data.cassandra.mapping.UserDefinedType;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
@AllArgsConstructor
@Builder
@Data
@UserDefinedType
public class GroupOfUser{
public GroupOfUser(){}
@PrimaryKey("group_id")
private Long groupId;
@Column("group_name")
private String groupName;
@Column("ver")
private int ver;
@Column("last_updated_date")
private Date lastUpdatedDate;
}
データの取得は単純にUserRepositoryからUserデータを取得し、Groupを返すだけで良い。
package org.debugroom.sample.cassandra.pattern1.domain.service;
// omit other import statement.
@Slf4j
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
UserRepository userRepository;
@Autowired
GroupRepository groupRepository;
// omit
@Override
public List<Group> getGroups(Long userId) {
List<GroupOfUser> groupsOfUser = getGroupsOfUser(userId);
return Lists.transform(groupsOfUser, new Function<GroupOfUser, Group>() {
@Override
public Group apply(GroupOfUser groupOfUser){
return mapper.map(groupOfUser, Group.class);
}
});
}
public List<GroupOfUser> getGroupsOfUser(Long userId){
return userRepository.findOne(userId).getGroups();
}
Note
ここではList<Group>を返却するためにList<GroupOfUser>を、GuavaのListsクラスを使って変換している。
指定したグループに所属する全てのユーザ一覧を取得する¶
前セクション「指定したユーザが属するグループの一覧を取得する」と同様、こちらは逆パターンであり、GroupエンティティにもUserデータのListを保持し、非正規化する。同様にUserクラスもGroupのデータを保持する必要があるため、相互にUser -> Group、Group -> Userの参照をもつと相互参照(循環参照)になってしまうため、ここでもGroup内にUserと同じプロパティをもつUserOfGroupをユーザ定義型クラスとして作成する。
package org.debugroom.sample.cassandra.pattern1.domain.entity;
// omit import statement
@AllArgsConstructor
@Builder
@Data
@Table("group")
public class Group {
public Group(){
}
@PrimaryKey("group_id")
private Long groupId;
// omit
@Column("users")
private List<UserOfGroup> users;
}
package org.debugroom.sample.cassandra.pattern1.domain.entity;
import java.util.Date;
import java.util.List;
import org.springframework.data.cassandra.mapping.Column;
import org.springframework.data.cassandra.mapping.PrimaryKey;
import org.springframework.data.cassandra.mapping.UserDefinedType;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
@AllArgsConstructor
@Builder
@Data
@UserDefinedType
public class UserOfGroup{
public UserOfGroup(){}
@PrimaryKey("user_id")
private Long userId;
@Column("user_name")
private String userName;
@Column("is_enabled")
private boolean isEnabled;
@Column("is_locked")
private boolean isLocked;
@Column("is_admin")
private boolean isAdmin;
@Column("ver")
private int ver;
@Column("last_updated_date")
private Date lastUpdatedDate;
}
Service実装クラスからはGroupRepositoryを介してデータを取得し、返却するだけで良い。
package org.debugroom.sample.cassandra.pattern1.domain.service;
// omit other import statement.
@Slf4j
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
UserRepository userRepository;
@Autowired
GroupRepository groupRepository;
// omit
@Override
public List<User> getUsersByGroupId(Long groupId) {
List<UserOfGroup> usersOfGroup = getUsersOfGroup(groupId);
return Lists.transform(usersOfGroup, new Function<UserOfGroup, User>(){
@Override
public User apply(UserOfGroup userOfGroup){
return mapper.map(userOfGroup, User.class);
}
});
}
public List<UserOfGroup> getUsersOfGroup(Long groupId){
return groupRepository.findOne(groupId).getUsers();
}
Note
ここではList<User>を返却するためにList<UserOfGroup>を、GuavaのListsクラスを使って変換している。
指定したグループに所属しない全てのユーザ一覧を取得する¶
ユースケース「特定の郵便番号を持たないユーザ一覧を取得する」と同じく、特定のグループに所属するユーザを全体のユーザから除外したリストを返却すれば良い。Service実装クラスは、
package org.debugroom.sample.cassandra.pattern1.domain.service;
// omit other import statement.
@Slf4j
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
UserRepository userRepository;
@Autowired
GroupRepository groupRepository;
// omit
@Override
public List<User> getNotUsersByGroupId(Long groupId) {
List<UserOfGroup> usersOfGroup = groupRepository.findOne(groupId).getUsers();
Map<Long, User> userMap = userRepository.findAllForMap();
for(UserOfGroup userOfGroup : usersOfGroup){
userMap.remove(userOfGroup.getUserId());
}
return new ArrayList<User>(userMap.values());
}
Note
UserRepository.findAllForMap()はユースケース「特定の郵便番号を持たないユーザ一覧を取得する」で作成したカスタムUserRepositoryクラスのメソッドである。
指定したユーザを指定したグループに追加する¶
前セクション「指定したユーザが属するグループの一覧を取得する」、「指定したグループに所属する全てのユーザ一覧を取得する」のユースケースにおいて、User及びGroupエンティティにそれぞれ非正規化されたデータが定義されている。そのため、各テーブルに相互に整合性が取れた形でデータを保存する必要がある。
package org.debugroom.sample.cassandra.pattern1.domain.service;
// omit other import statement.
@Slf4j
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
UserRepository userRepository;
@Autowired
GroupRepository groupRepository;
// omit
@Override
public Group addUserToGroup(Long userId, Long groupId) {
User user = userRepository.findOne(userId);
Group group = groupRepository.findOne(groupId);
group.getUsers().add(UserOfGroup.builder()
.userId(userId)
.userName(user.getUserName())
.isEnabled(user.isEnabled())
.isLocked(user.isLocked())
.isAdmin(user.isAdmin())
.ver(0)
.lastUpdatedDate(new Date())
.build());
user.getGroups().add(GroupOfUser.builder()
.groupId(groupId)
.groupName(group.getGroupName())
.ver(0)
.lastUpdatedDate(new Date())
.build());
userRepository.save(user);
return groupRepository.save(group);
}
指定したユーザをグループから除外する¶
前セクション「指定したユーザを指定したグループに追加する」と同様、非正規化されたデータに対し、双方データ更新を行う必要がある。 Listデータからremove()すると実装が複雑化するので、除外しないデータだけで新たなListを作成し、更新する実装とする。
package org.debugroom.sample.cassandra.pattern1.domain.service;
// omit other import statement.
@Slf4j
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
UserRepository userRepository;
@Autowired
GroupRepository groupRepository;
// omit
@Override
public Group deleteUserFromGroup(Long userId, Long groupId) {
User user = userRepository.findOne(userId);
List<GroupOfUser> groupsOfUser = new ArrayList<GroupOfUser>();
for(GroupOfUser groupOfUser : user.getGroups()){
if(groupId != groupOfUser.getGroupId()){
groupsOfUser.add(groupOfUser);
}
}
user.setGroups(groupsOfUser);
Group group = groupRepository.findOne(groupId);
List<UserOfGroup> usersOfGroup = new ArrayList<UserOfGroup>();
for(UserOfGroup userOfGroup : group.getUsers()){
if(userId != userOfGroup.getUserId()){
usersOfGroup.add(userOfGroup);
}
}
group.setUsers(usersOfGroup);
userRepository.save(user);
return groupRepository.save(group);
}
指定したグループを削除し、ユーザが所属するグループの情報を更新する¶
前セクション「指定したユーザを指定したグループに追加する」と同様、非正規化されたデータに対し、双方データ更新を行う必要がある。 Listデータからremove()すると実装が複雑化するので、除外しないデータだけで新たなListを作成し、更新する実装とする。
package org.debugroom.sample.cassandra.pattern1.domain.service;
// omit other import statement.
@Slf4j
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
UserRepository userRepository;
@Autowired
GroupRepository groupRepository;
// omit
@Override
public Group deleteGroup(Long groupId) {
Group deleteGroup = groupRepository.findOne(groupId);
for(UserOfGroup userOfGroup : deleteGroup.getUsers()){
User user = userRepository.findOne(userOfGroup.getUserId());
List<GroupOfUser> groupsOfUser = new ArrayList<GroupOfUser>();
for(GroupOfUser groupOfUser : user.getGroups()){
if(groupOfUser.getGroupId() != groupId){
groupsOfUser.add(groupOfUser);
}
}
user.setGroups(groupsOfUser);
userRepository.save(user);
}
groupRepository.delete(deleteGroup);
return deleteGroup;
}
指定されたユーザを削除し、グループのユーザ一覧を更新する¶
ユーザデータを削除するにあたり、これまで非正規化したテーブルなど含めて全てデータ更新する必要がある。
package org.debugroom.sample.cassandra.pattern1.domain.service;
// omit other import statement.
@Slf4j
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
UserRepository userRepository;
@Autowired
AddressRepository addressRepository;
@Autowired
EmailRepository emailRepository;
@Autowired
GroupRepository groupRepository;
// omit
@Override
public User deleteUser(Long userId) {
User deleteUser = userRepository.findOne(userId);
for(GroupOfUser groupOfUser : deleteUser.getGroups()){
Group group = groupRepository.findOne(groupOfUser.getGroupId());
List<UserOfGroup> usersOfGroup = new ArrayList<UserOfGroup>();
for(UserOfGroup userOfGroup : group.getUsers()){
if(userId != userOfGroup.getUserId()){
usersOfGroup.add(userOfGroup);
}
}
group.setUsers(usersOfGroup);
groupRepository.save(group);
}
for(Address address : addressRepository.findByAddresspkUserId(userId)){
addressRepository.delete(address);
}
for(Email email : emailRepository.findByUserId(userId)){
emailRepository.delete(email);
}
for(Credential credential : credentialRepository.findByUserId(userId)){
credentialRepository.delete(credential);
}
userRepository.delete(deleteUser);
return deleteUser;
}
Todo
ノード数を増やした状態で検証し、性能問題が起きないか検証を行う。
パターン2(リレーショナルモデル)を中心としたデータモデル¶
効率的なデータベースアクセスの検証のため、リレーショナルに近いデータモデルを構築する。 本サンプルでは、以下の構成をパターン2として実装例を記述する。
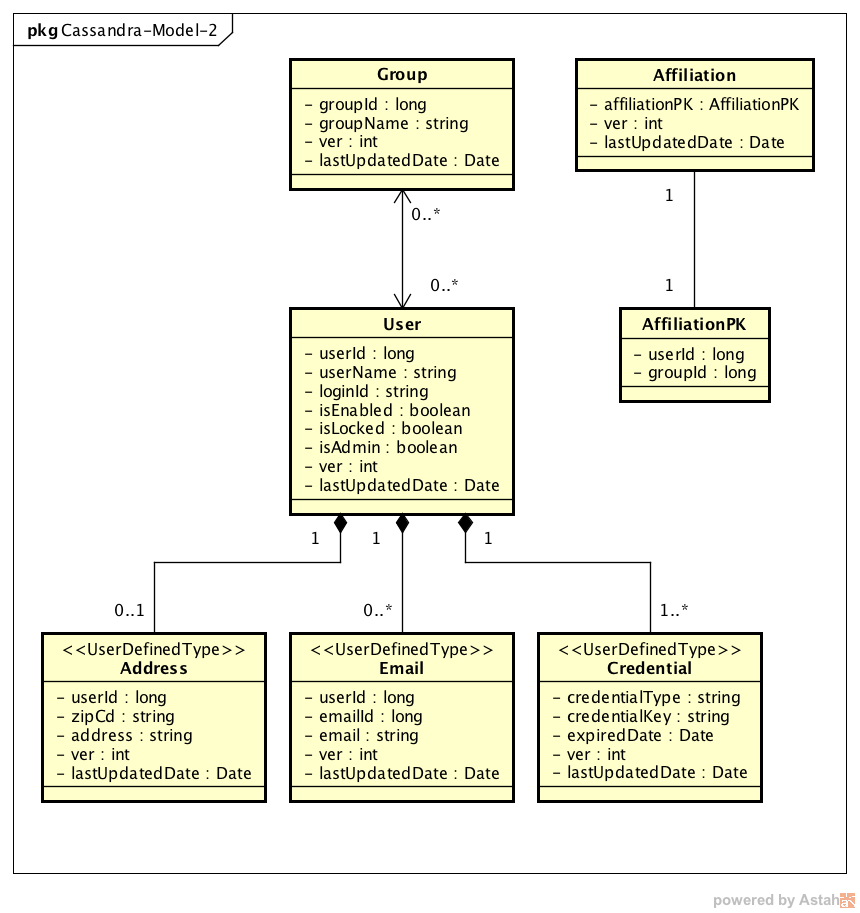
テーブルとして定義する、各エンティティクラスの実装は以下の通り。
package org.debugroom.sample.cassandra.pattern2.domain.entity;
import java.util.Date;
import java.util.List;
import org.springframework.data.annotation.Transient;
import org.springframework.data.cassandra.mapping.Table;
import org.springframework.data.cassandra.mapping.Column;
import org.springframework.data.cassandra.mapping.PrimaryKey;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
@AllArgsConstructor
@Builder
@Data
@Table("users")
public class User {
public User(){
}
@PrimaryKey("user_id")
private Long userId;
@Column("user_name")
private String userName;
@Column("login_id")
private String loginId;
@Column("credentials")
private List<Credential> credentials;
@Column("is_enabled")
private boolean isEnabled;
@Column("is_locked")
private boolean isLocked;
@Column("is_admin")
private boolean isAdmin;
@Column("address")
private Address address;
@Column("emails")
List<Email> emails;
@Column("ver")
private int ver;
@Column("last_updated_date")
private Date lastUpdatedDate;
@Transient
private List<Group> groups;
}
package org.debugroom.sample.cassandra.pattern2.domain.entity;
import java.util.Date;
import java.util.List;
import org.springframework.data.annotation.Transient;
import org.springframework.data.cassandra.mapping.Column;
import org.springframework.data.cassandra.mapping.PrimaryKey;
import org.springframework.data.cassandra.mapping.Table;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
@AllArgsConstructor
@Builder
@Data
@Table("group")
public class Group {
public Group(){
}
@PrimaryKey("group_id")
private Long groupId;
@Column("group_name")
private String groupName;
@Column("ver")
private int ver;
@Column("last_updated_date")
private Date lastUpdatedDate;
@Transient
private List<User> users;
}
package org.debugroom.sample.cassandra.pattern2.domain.entity;
import java.util.Date;
import org.springframework.data.cassandra.mapping.Column;
import org.springframework.data.cassandra.mapping.PrimaryKey;
import org.springframework.data.cassandra.mapping.Table;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
@AllArgsConstructor
@Builder
@Data
@Table("affiliation")
public class Affiliation {
public Affiliation(){
}
@PrimaryKey("affiliationpk")
private AffiliationPK affiliationpk;
@Column("ver")
private int ver;
@Column("last_updated_date")
private Date lastUpdatedDate;
}
package org.debugroom.sample.cassandra.pattern2.domain.entity;
import java.io.Serializable;
import org.springframework.cassandra.core.PrimaryKeyType;
import org.springframework.data.cassandra.mapping.PrimaryKeyClass;
import org.springframework.data.cassandra.mapping.PrimaryKeyColumn;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
@AllArgsConstructor
@Builder
@Data
@PrimaryKeyClass
public class AffiliationPK implements Serializable{
private static final long serialVersionUID = 6634695143792297552L;
public AffiliationPK(){}
@PrimaryKeyColumn(name = "user_id", ordinal = 0, type = PrimaryKeyType.CLUSTERED)
private Long userId;
@PrimaryKeyColumn(name = "group_id", ordinal = 1, type = PrimaryKeyType.PARTITIONED)
private Long groupId;
}
ユーザ定義型クラスは以下の通り。
package org.debugroom.sample.cassandra.pattern2.domain.entity;
import java.util.Date;
import org.springframework.data.cassandra.mapping.Column;
import org.springframework.data.cassandra.mapping.UserDefinedType;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
@AllArgsConstructor
@Builder
@Data
@UserDefinedType
public class Address {
@Column("zip_cd")
private String zipCd;
@Column("address")
private String address;
@Column("ver")
private int ver;
@Column("last_updated_date")
private Date lastUpdatedDate;
}
package org.debugroom.sample.cassandra.pattern2.domain.entity;
import java.util.Date;
import org.springframework.data.cassandra.mapping.Column;
import org.springframework.data.cassandra.mapping.UserDefinedType;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
@AllArgsConstructor
@Builder
@Data
@UserDefinedType
public class Email {
@Column("email")
private String email;
@Column("ver")
private int ver;
@Column("last_updated_date")
private Date lastUpdatedDate;
}
package org.debugroom.sample.cassandra.pattern2.domain.entity;
import java.util.Date;
import org.springframework.data.cassandra.mapping.Column;
import org.springframework.data.cassandra.mapping.UserDefinedType;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
@AllArgsConstructor
@Builder
@Data
@UserDefinedType
public class Credential {
@Column("credential_type")
private String credentialType;
@Column("credential_key")
private String credentialKey;
@Column("expired_date")
private Date expiredDate;
@Column("ver")
private int ver;
@Column("last_updated_date")
private Date lastUpdatedDate;
}
上記のエンティティクラスと対応づくテーブル定義は以下の通りである。
CREATE TYPE sample.address (
address text,
last_updated_date timestamp,
ver int,
zip_cd text
);
CREATE TYPE sample.credential (
credential_key text,
credential_type text,
expired_date timestamp,
last_updated_date timestamp,
ver int
);
CREATE TYPE sample.email (
email text,
last_updated_date timestamp,
ver int
);
CREATE TABLE sample.group (
group_id bigint PRIMARY KEY,
group_name text,
last_updated_date timestamp,
ver int
);
CREATE TABLE sample.users (
user_id bigint PRIMARY KEY,
address frozen<address>,
credentials list<frozen<credential>>,
emails list<frozen<email>>,
is_admin boolean,
is_enabled boolean,
is_locked boolean,
last_updated_date timestamp,
login_id text,
user_name text,
ver int
)
CREATE TABLE sample.affiliation (
group_id bigint,
user_id bigint,
last_updated_date timestamp,
ver int,
PRIMARY KEY (group_id, user_id)
)
全てのユーザを検索する¶
Service実装クラスでは、パターン1とも同様に、CrudRepositoryインターフェースを継承したインターフェースのメソッドを呼び出せばよい。 Userテーブルのすべてのデータを検索する場合は、UserRepository.findAll()を使用する。
package org.debugroom.sample.cassandra.pattern2.domain.service;
// omit import statements.
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
UserRepository userRepository;
@Override
public List<User> getUsers(){
return (List<User>)userRepository.findAll();
}
全ての住所を検索する¶
Addressクラスはユーザ定義クラスであり、Addressテーブルを定義していない。そのため、すべての住所を取得するには、Userデータから住所データを取得し、List型で返却する。
package org.debugroom.sample.cassandra.pattern2.domain.service;
// omit import statements.
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
UserRepository userRepository;
@Override
public List<User> getUsers(){
return (List<User>)userRepository.findAll();
}
@Override
public List<Address> getAddresses() {
List<User> users = getUsers();
List<Address> addresses = new ArrayList<Address>();
for(User user : users){
addresses.add(user.getAddress());
}
return addresses;
}
Todo
テーブルを作成し、非正規化した場合に比べて、データ数に応じてどれだけ差が出るか検証
全てのメールアドレスを検索する¶
Address同様、Emailクラスはユーザ定義クラスであり、Emailテーブルを定義していない。そのため、すべてのEmailを取得するには、UserデータからEmailデータを取得し、List型で返却する。
package org.debugroom.sample.cassandra.pattern2.domain.service;
// omit import statements.
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
UserRepository userRepository;
@Override
public List<User> getUsers(){
return (List<User>)userRepository.findAll();
}
@Override
public List<Email> getEmails() {
List<User> users = getUsers();
List<Email> allEmails = new ArrayList<Email>();
for(User user : users){
if(null != user.getEmails()){
allEmails.addAll(user.getEmails());
}
}
return allEmails;
}
全てのグループを検索する¶
パターン1とも同様に、CrudRepositoryインターフェースを継承したインターフェースのメソッドを呼び出せばよい。 Groupテーブルのすべてのデータを検索する場合は、GroupRepository.findAll()を使用する。
package org.debugroom.sample.cassandra.pattern2.domain.service;
// omit import statements.
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
GroupRepository groupRepository;
@Override
public List<Group> getGroups() {
return (List<Group>) groupRepository.findAll();
}
特定のユーザを検索する¶
パターン1の場合同様、特定のユーザを検索する場合は、CrudRepositoryインターフェースが持つfindOneメソッドを実行すれば良い。
package org.debugroom.sample.cassandra.pattern2.domain.service;
// omit import statements.
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
UserRepository userRepository;
@Override
public User getUser(Long userId) {
return userRepository.findOne(userId);
}
特定のユーザのアドレスを検索する¶
特定のユーザのアドレスは、テーブルUserの中にユーザ定義クラスAddressの形で保持しているので、ユーザデータを取得してアドレスデータをそのまま返せば良い。
package org.debugroom.sample.cassandra.pattern2.domain.service;
// omit import statements.
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
UserRepository userRepository;
@Override
public Address getAddress(Long userId) {
return userRepository.findOne(userId).getAddress();
}
特定のユーザがもつEmailアドレスを検索する¶
前セクション「特定のユーザのアドレス」と同様、テーブルUserの中にユーザ定義クラスEmailをList形式で保持しているので、ユーザデータを取得して、Emailデータをそのまま返せば良い。
package org.debugroom.sample.cassandra.pattern2.domain.service;
// omit import statements.
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
UserRepository userRepository;
@Override
public List<Email> getEmails(Long userId) {
return userRepository.findOne(userId).getEmails();
}
指定したグループ名を元にグループを検索する¶
パターン1と同様、GroupRepositoryインターフェースにfindByGroupNameメソッドを定義し、allow filteringオプションを付与したCQLを定義する。
package org.debugroom.sample.cassandra.pattern2.domain.repository;
import java.util.List;
import org.debugroom.sample.cassandra.pattern2.domain.entity.Group;
import org.springframework.data.cassandra.repository.Query;
import org.springframework.data.repository.CrudRepository;
public interface GroupRepository extends CrudRepository<Group, Long>{
// Use query adding allow filtering option or secondary index or materialized view.
@Query("select * from group where group_name = ?0 allow filtering")
public List<Group> findByGroupName(String groupName);
}
サービス実装クラスからは、上記のメソッドを呼び出す。
package org.debugroom.sample.cassandra.pattern2.domain.service;
// omit import statements.
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
GroupRepository groupRepository;
@Override
public List<Group> getGroups(String groupName) {
return groupRepository.findByGroupName(groupName);
}
特定の郵便番号を持つユーザ一覧を取得する¶
郵便番号は、ユーザ定義型クラスのプロパティであり、Userテーブルの中でキーとして使用することはできない。検索キーとして用いるのであれば、パターン1と同様、住所に関する情報を非正規化して別のテーブルに切り出すしかない。非正規化を選ばない例として、ここでは、アプリケーションで、取得したユーザ情報から該当する郵便番号と一致する方法で実装する。
package org.debugroom.sample.cassandra.pattern2.domain.service;
// omit import statements.
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
UserRepository userRepository;
@Override
public List<User> getUsers(){
return (List<User>)userRepository.findAll();
}
@Override
public List<User> getUsers(String zipCd) {
List<User> users = new ArrayList<User>();
for(User user : getUsers()){
if(null != user.getAddress()
&& user.getAddress().getZipCd().equals(zipCd)){
users.add(user);
}
}
return users;
}
しかし、このサービス層で対象のデータを検索する実装を行う方法は、当然ユーザテーブルから取得したデータ件数が多ければ多いほど、線形的に処理時間が増加するため、データ件数が膨大な場合は推奨はされない方法である。そのため、Cassandraからデータ取得したResultSetからエンティティクラスにマッピングする際に、郵便番号をキーとしたMap型でユーザ一覧を返却することにより、処理時間の高速化を行う。パターン1の「特定の番号を持たないユーザ一覧を取得する」場合と同様、Repositoryクラスを拡張し、郵便番号をキーとして、その郵便番号をもつユーザのリスト型をバリューにもつ、Mapを返却するメソッドをRepositoryクラスに作成する。
まず、カスタムのメソッドを持つ、インターフェースを作成する。
package org.debugroom.sample.cassandra.pattern2.domain.repository;
import java.util.Map;
import java.util.List;
import org.debugroom.sample.cassandra.pattern2.domain.entity.User;
public interface UserRepositoryCustom {
public Map<String, List<User>> findAllForMappedListByZipCd();
}
作成したインターフェースをUserRepositoryクラスに継承させる。
package org.debugroom.sample.cassandra.pattern2.domain.repository;
// omit
public interface UserRepository extends CrudRepository<User, Long>, UserRepositoryCustom{
// omit
}
メソッドを実装したクラスを作成する。また、ResultSetExtractorを拡張し、Map<String, List<User>>型でユーザ一覧を返却する、UserMappedListByZipCdExtractorクラスを作成する。
package org.debugroom.sample.cassandra.pattern2.domain.repository.impl;
import java.util.List;
import java.util.Map;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.data.cassandra.core.CassandraAdminOperations;
import org.springframework.data.cassandra.core.CassandraOperations;
import org.springframework.data.repository.NoRepositoryBean;
import com.datastax.driver.core.querybuilder.QueryBuilder;
import com.datastax.driver.core.querybuilder.Select;
import org.debugroom.sample.cassandra.pattern2.domain.entity.User;
import org.debugroom.sample.cassandra.pattern2.domain.repository.UserRepositoryCustom;
@NoRepositoryBean
public class UserRepositoryImpl implements UserRepositoryCustom{
@Autowired
@Qualifier("cassandraTemplate")
CassandraOperations cassandraOperations;
@Override
public Map<String, List<User>> findAllForMappedListByZipCd() {
Select select = QueryBuilder.select().from("users");
return cassandraOperations.query(select, new UserMappedListByZipCdExtractor());
}
}
package org.debugroom.sample.cassandra.pattern2.domain.repository.impl;
import java.util.Map;
import java.util.List;
import java.util.ArrayList;
import java.util.HashMap;
import org.debugroom.sample.cassandra.pattern2.domain.entity.Address;
import org.debugroom.sample.cassandra.pattern2.domain.entity.Credential;
import org.debugroom.sample.cassandra.pattern2.domain.entity.Email;
import org.debugroom.sample.cassandra.pattern2.domain.entity.Group;
import org.debugroom.sample.cassandra.pattern2.domain.entity.User;
import org.springframework.cassandra.core.ResultSetExtractor;
import org.springframework.dao.DataAccessException;
import com.datastax.driver.core.ResultSet;
import com.datastax.driver.core.Row;
import com.datastax.driver.core.UDTValue;
import com.datastax.driver.core.exceptions.DriverException;
public class UserMappedListByZipCdExtractor implements
ResultSetExtractor<Map<String, List<User>>>{
@Override
@SuppressWarnings("unchecked")
public Map<String, List<User>> extractData(ResultSet resultSet)
throws DriverException, DataAccessException {
Map<String, List<User>> mappedLists = new HashMap<String, List<User>>();
while(resultSet.iterator().hasNext()){
Row row = resultSet.one();
UDTValue address = row.getUDTValue("address");
List<Email> emails = new ArrayList<Email>();
List<Credential> credentials = new ArrayList<Credential>();
List<Group> groups = new ArrayList<Group>();
User user = User.builder()
.userId(row.getLong("user_id"))
.userName(row.getString("user_name"))
.isEnabled(row.getBool("is_enabled"))
.isLocked(row.getBool("is_locked"))
.isAdmin(row.getBool("is_admin"))
.emails(emails)
.credentials(credentials)
.groups(groups)
.ver(row.getInt("ver"))
.lastUpdatedDate(row.getTimestamp("last_updated_date"))
.build();
String zipCd = null;
if(address != null){
zipCd = address.getString("zip_cd");
user.setAddress((Address.builder()
.zipCd(zipCd)
.address(address.getString("address"))
.ver(address.getInt("ver"))
.lastUpdatedDate(address.getTimestamp("last_updated_date"))
.build()));
}else{
zipCd = "No address data.";
}
for(UDTValue udtValue : (List<UDTValue>)row.getObject("emails")){
emails.add(Email.builder()
.email(udtValue.getString("email"))
.ver(udtValue.getInt("ver"))
.lastUpdatedDate(udtValue.getTimestamp("last_updated_date"))
.build());
}
for(UDTValue udtValue : (List<UDTValue>)row.getObject("credentials")){
credentials.add(Credential.builder()
.credentialType(udtValue.getString("credential_type"))
.credentialKey(udtValue.getString("credential_key"))
.expiredDate(udtValue.getTimestamp("expired_date"))
.ver(udtValue.getInt("ver"))
.lastUpdatedDate(udtValue.getTimestamp("last_updated_date"))
.build());
}
List<User> users = mappedLists.get(zipCd);
if(users == null){
users = new ArrayList<User>();
mappedLists.put(zipCd, users);
}
users.add(user);
}
return mappedLists;
}
}
サービスクラスからは、キーである郵便番号ごとにユーザリストがまとまっているため、指定されたキーのユーザデータを返却するだけで良い。
package org.debugroom.sample.cassandra.pattern2.domain.service;
// omit import statements.
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
UserRepository userRepository;
@Override
public List<User> getUsers(){
return (List<User>)userRepository.findAll();
}
@Override
public List<User> getUsers(String zipCd) {
Map<String, List<User>> usersMapByZipCd =
userRepository.findAllForMappedListByZipCd();
List<User> users = usersMapByZipCd.get(zipCd);
return users;
}
Todo
Cassandraのような分散データベースが、パターン1の方法で非正規化データを取得する場合に比べ、どの程度の件数が許容する性能の分岐点になるか目処感を検証しておく。
Note
パターン2のテーブル構成で性能を保つ別の一案として、非正規化せずに、アプリケーション起動時に郵便番号をキーとしたユーザ一覧をキャッシュとしてもつ実装も一案として実現は可能であるが、ユーザの郵便番号が変更されるたびにキャッシュを更新せねばならず、また分散データベース環境であるため、キャッシュを更新する実装が逆に著しく複雑になると予想されるため、除外する。
特定の郵便番号を持たないユーザ一覧を取得する¶
「特定の郵便番号を持つユーザ一覧を取得する」のユースケースの場合と同じで、全ユーザの中で、逆に郵便番号が一致しないユーザデータをList型で返却すれば良い。
Warning
この方法は、当然ユーザテーブルから取得したデータ件数が多ければ多いほど、線形的に処理時間が増加するため、データ件数が膨大な場合は推奨はされない方法である。
package org.debugroom.sample.cassandra.pattern2.domain.service;
// omit import statements.
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
UserRepository userRepository;
@Override
public List<User> getUsers(){
return (List<User>)userRepository.findAll();
}
@Override
public List<User> getNotUsers(String zipCd) {
List<User> users = new ArrayList<User>();
for(User user : getUsers()){
if(null != user.getAddress()
&& !user.getAddress().getZipCd().equals(zipCd)){
users.add(user);
}
}
return users;
}
こちらも前ユースケース「特定の郵便番号を持つユーザ一覧を取得する」場合と同様、データ数が多ければ、使用できない実装であるため、拡張したRepositoryクラスのfindAllForMappedListByZipCdメソッドを使用して取得したデータから、特定のキーを除外した結果を返すと良い。サービスクラスは以下のような実装になる。
package org.debugroom.sample.cassandra.pattern2.domain.service;
// omit import statements.
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
UserRepository userRepository;
@Override
public List<User> getUsers(){
return (List<User>)userRepository.findAll();
}
@Override
public List<User> getNotUsers(String zipCd) {
Map<String, List<User>> usersMapByZipCd =
userRepository.findAllForMappedListByZipCd();
usersMapByZipCd.remove(zipCd);
List<User> users = new ArrayList<User>();
for(Entry<String, List<User>> entry : usersMapByZipCd.entrySet()){
users.addAll(entry.getValue());
}
return users;
}
Note
パターン2のテーブル構成で性能を保つ別の一案として、非正規化せずに、アプリケーション起動時に郵便番号をキーとしたユーザ一覧をキャッシュとして構築し、データアクセス時にキャッシュを参照する実装も一案として実現は可能であるが、ユーザの住所情報や郵便番号が変更されるたびにキャッシュを更新せねばならず、また分散データベース環境であるため、キャッシュを更新する実装が逆に著しく複雑になると予想されるため、除外する。
指定されたユーザの住所を追加する¶
単純にUserテーブルのAddressプロパティにデータを追加すれば良い。NULLの場合は単純にデータ追加すればよいが、すでにAddressデータがある場合は、既存のデータを更新するロジックを実装する必要がある。
package org.debugroom.sample.cassandra.pattern2.domain.service;
// omit import statements.
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
UserRepository userRepository;
@Override
public List<User> getUsers(){
return (List<User>)userRepository.findAll();
}
@Override
public User addAddress(Long userId, String zipCd, String address) {
User user = getUser(userId);
if(null != user){
if(null == user.getAddress()){
Address addAddress = Address.builder()
.zipCd(zipCd)
.address(address)
.ver(0)
.lastUpdatedDate(new Date())
.build();
user.setAddress(addAddress);
}else{
Address updateAddress = user.getAddress();
updateAddress.setZipCd(zipCd);
updateAddress.setAddress(address);
updateAddress.setVer(updateAddress.getVer()+1);
updateAddress.setLastUpdatedDate(new Date());
}
userRepository.save(user);
}
return user;
}
指定されたユーザの住所を更新する¶
UserテーブルのAddressプロパティにデータを更新する。ロジックは前ユースケース「指定されたユーザの住所を追加する」と同じのため、そのまま利用する。
package org.debugroom.sample.cassandra.pattern2.domain.service;
// omit import statements.
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Override
public User updateAddress(Long userId, String zipCd, String address) {
return addAddress(userId, zipCd, address);
}
指定されたユーザの住所を削除する¶
Userテーブルのアドレスプロパティのデータを削除する。エンティティクラスを取得し、NULLをセットする。
package org.debugroom.sample.cassandra.pattern2.domain.service;
// omit import statements.
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
UserRepository userRepository;
@Override
public List<User> getUsers(){
return (List<User>)userRepository.findAll();
}
@Override
public User deleteAddress(Long userId) {
User user = getUser(userId);
if(null != user){
user.setAddress(null);
}
return user;
}
特定のメールアドレスを持つユーザを検索する¶
メールアドレスも、ユーザ定義型クラスEmailのプロパティであり、ユーザテーブルに1対多の形式でリスト型で保持されているので、検索キーとして利用することはできない。従って、サービスクラス上で、対象のメールアドレスを検索するロジックを実装する必要があるが、ユースケース「特定の郵便番号を持つユーザを検索する」場合と同様に、順次検索では、ユーザデータ量に比例して、線形的に増加する。
package org.debugroom.sample.cassandra.pattern2.domain.service;
// omit import statements.
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
UserRepository userRepository;
@Override
public List<User> getUsers(){
return (List<User>)userRepository.findAll();
}
@Override
public User getUserByEmail(String email) {
for(User user : getUsers()){
if(null != user.getEmails()){
for(Email target: user.getEmails()){
if(target.getEmail().equals(email)){
return user;
}
}
}
}
return null;
}
そのため、ResultSetからのエンティティクラスのマッピング時に、メールアドレスをキーとしたMap型でユーザ一覧を作成する方式で実装を行う。UserRepositoryの拡張インタンーフェースにカスタムメソッドを定義する。
package org.debugroom.sample.cassandra.pattern2.domain.repository;
import java.util.Map;
import java.util.List;
import org.debugroom.sample.cassandra.pattern2.domain.entity.User;
public interface UserRepositoryCustom {
//omit
public Map<String, User> findAllForMappByEmail();
}
上記の実装クラスは以下の通りである。また、cassandraOperation.query()メソッドの引数として指定する、ResultSetExtractorを継承して、メールアドレスをキーに、Map<String, User>型のユーザ一覧を返却するよう、UserMapByEmailExtractorを実装する。
package org.debugroom.sample.cassandra.pattern2.domain.repository.impl;
import java.util.List;
import java.util.Map;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.data.cassandra.core.CassandraAdminOperations;
import org.springframework.data.cassandra.core.CassandraOperations;
import org.springframework.data.repository.NoRepositoryBean;
import com.datastax.driver.core.querybuilder.QueryBuilder;
import com.datastax.driver.core.querybuilder.Select;
import org.debugroom.sample.cassandra.pattern2.domain.entity.User;
import org.debugroom.sample.cassandra.pattern2.domain.repository.UserRepositoryCustom;
@NoRepositoryBean
public class UserRepositoryImpl implements UserRepositoryCustom{
@Autowired
@Qualifier("cassandraTemplate")
CassandraOperations cassandraOperations;
@Override
public Map<String, User> findAllForMappByEmail() {
Select select = QueryBuilder.select().from("users");
return cassandraOperations.query(select, new UserMapByEmailExtractor());
}
}
package org.debugroom.sample.cassandra.pattern2.domain.repository.impl;
import java.util.Map;
import java.util.List;
import java.util.ArrayList;
import java.util.HashMap;
import org.debugroom.sample.cassandra.pattern2.domain.entity.Address;
import org.debugroom.sample.cassandra.pattern2.domain.entity.Credential;
import org.debugroom.sample.cassandra.pattern2.domain.entity.Email;
import org.debugroom.sample.cassandra.pattern2.domain.entity.User;
import org.springframework.cassandra.core.ResultSetExtractor;
import org.springframework.dao.DataAccessException;
import com.datastax.driver.core.ResultSet;
import com.datastax.driver.core.Row;
import com.datastax.driver.core.UDTValue;
import com.datastax.driver.core.exceptions.DriverException;
public class UserMapByEmailExtractor implements ResultSetExtractor<Map<String, User>>{
@SuppressWarnings("unchecked")
@Override
public Map<String, User> extractData(ResultSet resultSet)
throws DriverException, DataAccessException {
Map<String, User> mappedUser = new HashMap<String, User>();
while(resultSet.iterator().hasNext()){
Row row = resultSet.one();
UDTValue address = row.getUDTValue("address");
List<Email> emails = new ArrayList<Email>();
List<Credential> credentials = new ArrayList<Credential>();
User user = User.builder()
.userId(row.getLong("user_id"))
.userName(row.getString("user_name"))
.isEnabled(row.getBool("is_enabled"))
.isLocked(row.getBool("is_locked"))
.isAdmin(row.getBool("is_admin"))
.emails(emails)
.credentials(credentials)
.ver(row.getInt("ver"))
.lastUpdatedDate(row.getTimestamp("last_updated_date"))
.build();
if(address != null){
user.setAddress(Address.builder()
.zipCd(address.getString("zip_cd"))
.address(address.getString("address"))
.ver(address.getInt("ver"))
.lastUpdatedDate(address.getTimestamp("last_updated_date"))
.build());
}
for(UDTValue udtValue : (List<UDTValue>)row.getObject("emails")){
String email = udtValue.getString("email");
emails.add(Email.builder()
.email(email)
.ver(udtValue.getInt("ver"))
.lastUpdatedDate(udtValue.getTimestamp("last_updated_date"))
.build());
mappedUser.put(email, user);
}
for(UDTValue udtValue : (List<UDTValue>)row.getObject("credentials")){
credentials.add(Credential.builder()
.credentialType(udtValue.getString("credential_type"))
.credentialKey(udtValue.getString("credential_key"))
.expiredDate(udtValue.getTimestamp("expired_date"))
.ver(udtValue.getInt("ver"))
.lastUpdatedDate(udtValue.getTimestamp("last_updated_date"))
.build());
}
}
return mappedUser;
}
}
サービス実装クラスでは、キーとなるemailを指定して、一致するUserデータを返却すれば良い。
package org.debugroom.sample.cassandra.pattern2.domain.service;
// omit import statements.
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
UserRepository userRepository;
@Override
public User getUserByEmail(String email) {
Map<String, User> usersMapByEmail = userRepository.findAllForMappByEmail();
return usersMapByEmail.get(email);
}
指定されたユーザのメールアドレスを追加する¶
メールアドレスはユーザ定義クラスEmailのプロパティであり、Userテーブルに保持されているので、対象のデータを取得して、Emailデータを追加すれば良い。
package org.debugroom.sample.cassandra.pattern2.domain.service;
// omit import statements.
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
UserRepository userRepository;
@Override
public User addEmail(Long userId, String email) {
User user = userRepository.findOne(userId);
user.getEmails().add(Email.builder()
.email(email)
.ver(0)
.lastUpdatedDate(new Date())
.build());
userRepository.save(user);
return user;
}
指定されたユーザをメールアドレスを含めて追加する¶
ユースケース「指定されたユーザのメールアドレス」を追加すると同様、Userクラスにユーザ定義クラスEmailを含め、必要なデータをセットして追加すればよい。
package org.debugroom.sample.cassandra.pattern2.domain.service;
// omit import statements.
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
UserRepository userRepository;
@Override
public User addUserWithEmail(Long userId, String userName, String email) {
List<Email> emails = new ArrayList<Email>();
User user = User.builder()
.userId(userId)
.userName(userName)
.isEnabled(true)
.isLocked(false)
.isAdmin(false)
.emails(emails)
.ver(0)
.lastUpdatedDate(new Date())
.build();
emails.add(Email.builder()
.email(email)
.ver(0)
.lastUpdatedDate(new Date())
.build());
return userRepository.save(user);
}
指定されたユーザのメールアドレスを更新する¶
メールアドレスはユーザ定義型クラスとしてUserテーブルに複数保持されているので、対象のEmailと一致したものを更新するロジックを実装すれば良い。
package org.debugroom.sample.cassandra.pattern2.domain.service;
// omit import statements.
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
UserRepository userRepository;
@Override
public User updateEmail(Long userId, String email, String newEmail) {
User user = userRepository.findOne(userId);
if(null != user){
for(Email target : user.getEmails()){
if(email.equals(target.getEmail())){
target.setEmail(newEmail);
}
}
}
return userRepository.save(user);
}
指定されたユーザのメールアドレスを1件削除する¶
メールアドレスはユーザ定義型クラスとしてUserテーブルに複数保持されているので、対象のEmailと一致したものを削除するロジックを実装すれば良い。ループ処理の中でデータをListから削除するのはコードが複雑になるので、削除対象以外のデータ以外のリストを新たに作成して、保存し直す形で実装する。
package org.debugroom.sample.cassandra.pattern2.domain.service;
// omit import statements.
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
UserRepository userRepository;
@Override
public User deleteEmail(Long userId, String email) {
User user = userRepository.findOne(userId);
List<Email> newEmails = new ArrayList<Email>();
for(Email target : user.getEmails()){
if(!email.equals(target.getEmail())){
newEmails.add(target);
}
}
user.setEmails(newEmails);
return userRepository.save(user);
}
指定されたユーザのメールアドレスを全件削除する¶
メールアドレスはユーザ定義型クラスとしてUserテーブルに複数保持されているので、NULLをセットし直して再保存することで削除する。
package org.debugroom.sample.cassandra.pattern2.domain.service;
// omit import statements.
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
UserRepository userRepository;
@Override
public User deleteEmails(Long userId) {
User user = userRepository.findOne(userId);
user.setEmails(null);
return userRepository.save(user);
}
指定したユーザが属するグループの一覧を取得する¶
指定したユーザが所属するグループは、リレーショナルモデルでいえば、通常、関連実体である「所属」を作ることにより、ユーザとグループがそれぞれN:Nの関係になるところを、それぞれ1:Nの関係とし、指定したユーザIDをキーにテーブルを結合していくことで、データの取得が可能である。これと同様に、ユーザIDとグループIDのキーから構成されるAffiliationテーブルを作成し、ユーザIDをキーに、ユーザが所属するグループのIDの一覧を取得し、それをもとにグループ一覧を検索する方法で実装を行う。
package org.debugroom.sample.cassandra.pattern2.domain.entity;
import java.util.Date;
import org.springframework.data.cassandra.mapping.Column;
import org.springframework.data.cassandra.mapping.PrimaryKey;
import org.springframework.data.cassandra.mapping.Table;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
@AllArgsConstructor
@Builder
@Data
@Table("affiliation")
public class Affiliation {
public Affiliation(){
}
@PrimaryKey("affiliationpk")
private AffiliationPK affiliationpk;
@Column("ver")
private int ver;
@Column("last_updated_date")
private Date lastUpdatedDate;
}
package org.debugroom.sample.cassandra.pattern2.domain.entity;
import java.io.Serializable;
import org.springframework.cassandra.core.PrimaryKeyType;
import org.springframework.data.cassandra.mapping.PrimaryKeyClass;
import org.springframework.data.cassandra.mapping.PrimaryKeyColumn;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
@AllArgsConstructor
@Builder
@Data
@PrimaryKeyClass
public class AffiliationPK implements Serializable{
private static final long serialVersionUID = 6634695143792297552L;
public AffiliationPK(){}
@PrimaryKeyColumn(name = "user_id", ordinal = 0, type = PrimaryKeyType.CLUSTERED)
private Long userId;
@PrimaryKeyColumn(name = "group_id", ordinal = 1, type = PrimaryKeyType.PARTITIONED)
private Long groupId;
}
当サンプルでは、後述するユースケース「指定したグループに所属する全てのユーザ一覧を取得する」のために、AffiliationPKのgroup_idをパーティションキーに設定している。 そのため、クラスタカラムであるユーザIDをキーとして、そのユーザが所属するグループ一覧を取得する場合、ALLOW FILTERINGオプションを付与する必要がある。AffiliationRepositoryクラスでは、命名規約に従い、以下の通り、findByAffiliationpkUserId(Long userId)を作成し、@QueryでALLOW FILTERINGオプションを付与したCQLを記述する。
package org.debugroom.sample.cassandra.pattern2.domain.repository;
import java.util.List;
import org.springframework.data.cassandra.repository.Query;
import org.springframework.data.repository.CrudRepository;
import org.debugroom.sample.cassandra.pattern2.domain.entity.Affiliation;
import org.debugroom.sample.cassandra.pattern2.domain.entity.AffiliationPK;
public interface AffiliationRepository extends CrudRepository<Affiliation, AffiliationPK>{
@Query("select * from affiliation where user_id =?0 allow filtering")
public List<Affiliation> findByAffiliationpkUserId(Long userId);
}
サービスクラスでは、取得した特定のユーザの所属するグループの一覧のリストを作成し、GroupRepositoryにて、IN句を使用してグループ一覧データを取得するロジックを実装する。
package org.debugroom.sample.cassandra.pattern2.domain.service;
// omit import statements.
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
UserRepository userRepository;
@Override
public List<Group> getGroups(Long userId) {
List<Affiliation> affiliations =
affiliationRepository.findByAffiliationpkUserId(userId);
List<Long> groupIds = new ArrayList<Long>();
for(Affiliation affiliation : affiliations){
groupIds.add(affiliation.getAffiliationpk().getGroupId());
}
List<Group> groups = groupRepository.findByGroupIdIn(groupIds);
return groups;
}
IN句を使用したCQLの実行のために、以下の通り、GroupRepositoryクラスに、Spring Dataのメソッド命名規約に基づき、findByGroupIdIn(List<Long> groupIds)メソッドを作成する。
package org.debugroom.sample.cassandra.pattern2.domain.repository;
// omit
public interface GroupRepository extends CrudRepository<Group, Long>{
// omit
public List<Group> findByGroupIdIn(List<Long> groupIds);
}
Warning
パーティションキーはデータをどのノードに配置するか決定するキーであるため、基本的には条件検索する場合、指定が必須である。ALLOW FILTERオプションを指定すると、クラスタカラムキーのみで検索が可能にはなるが、各ノードごとに全て問い合わせする必要があるため、著しくパフォーマンス低下する可能性があることに注意。
この実装方法では、たくさんのノードが存在する場合、パフォーマンスが著しく低下することが予想されるため、所属テーブルの全件データを取得したResultSetとエンティティクラスをマッピングする際に、ユーザIDをキーとして、グループIDのリストを保持するMap型でデータ返却し、それをもとにグループの一覧を取得する実装に変更する。
Map型でデータ返却するために、AffiliationRepositoryのカスタムRepositoryクラスを作成する。
package org.debugroom.sample.cassandra.pattern2.domain.repository;
import java.util.List;
import java.util.Map;
public interface AffiliationRepositoryCustom {
public Map<Long, List<Long>> findGroupIdsMapByUserId();
}
カスタムインターフェースをAffiliationRepositoryに継承させる。
package org.debugroom.sample.cassandra.pattern2.domain.repository;
// omit.
public interface AffiliationRepository extends CrudRepository<Affiliation, AffiliationPK>, AffiliationRepositoryCustom{
// omit.
}
サービス実装クラスでは、以下の通り、AffiliationMapByUserIdExtractorクラスを指定して、クエリ実行を行う。
package org.debugroom.sample.cassandra.pattern2.domain.repository.impl;
import java.util.List;
import java.util.Map;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.data.cassandra.core.CassandraOperations;
import org.springframework.data.repository.NoRepositoryBean;
import com.datastax.driver.core.querybuilder.QueryBuilder;
import com.datastax.driver.core.querybuilder.Select;
import org.debugroom.sample.cassandra.pattern2.domain.repository.AffiliationRepositoryCustom;
@NoRepositoryBean
public class AffiliationRepositoryImpl implements AffiliationRepositoryCustom{
@Autowired
@Qualifier("cassandraTemplate")
CassandraOperations cassandraOperations;
@Override
public Map<Long, List<Long>> findGroupIdsMapByUserId() {
Select select = QueryBuilder.select().from("affiliation");
return cassandraOperations.query(select, new AffiliationMapByUserIdExtractor());
}
}
AffiliationMapByUserIdExtractorでは、ユーザIDをキーにして、所属するグループのIDの一覧をMap型で返却する。
package org.debugroom.sample.cassandra.pattern2.domain.repository.impl;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.springframework.cassandra.core.ResultSetExtractor;
import org.springframework.dao.DataAccessException;
import com.datastax.driver.core.ResultSet;
import com.datastax.driver.core.Row;
import com.datastax.driver.core.exceptions.DriverException;
public class AffiliationMapByUserIdExtractor implements ResultSetExtractor<Map<Long, List<Long>>>{
@Override
public Map<Long, List<Long>> extractData(ResultSet resultSet)
throws DriverException, DataAccessException {
Map<Long, List<Long>> groupIdsMap = new HashMap<Long, List<Long>>();
while(resultSet.iterator().hasNext()){
Row row = resultSet.one();
Long userId = row.getLong("user_id");
List<Long> groupIds = groupIdsMap.get(userId);
if(null == groupIds){
groupIds = new ArrayList<Long>();
groupIdsMap.put(userId, groupIds);
}
groupIds.add(row.getLong("group_id"));
}
return groupIdsMap;
}
}
従って、サービス実装クラスでは、取得したMapの中で対象のユーザIDをキーにグループIDを取得し、そのグループIDをキーのリストとして、IN句を使用した検索を行う。
package org.debugroom.sample.cassandra.pattern2.domain.service;
// omit import statements.
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
UserRepository userRepository;
@Override
public List<Group> getGroups(Long userId) {
Map<Long, List<Long>> groupIdsMap = affiliationRepository.findGroupIdsMapByUserId();
List<Group> groups = groupRepository.findByGroupIdIn(groupIdsMap.get(userId));
return groups;
}
..todo:: IN句を使った検索と、カスタムRepositoryクラス+ResultSetExtractorを作成して、マッピング時にインデックスを作って(Map型)で実施する場合、パターン1で非正規化する場合に比べて、どの程度のデータカーディナリティで性能のパフォーマンスが異なってくるか検証が必要。
指定したグループに所属する全てのユーザ一覧を取得する¶
指定したグループに所属するユーザは、リレーショナルモデルでいえば、通常、関連実体である「所属」を作ることにより、ユーザとグループがそれぞれN:Nの関係になるところを、それぞれ1:Nの関係とし、指定したグループIDをキーにテーブルを結合していくことでデータの取得が可能である。ここでは、前ユースケース「指定したユーザが属するグループの一覧を取得する」のリレーショナルモデルと同様に関連実体テーブル「所属」から、グループIDをキーにグループに所属するユーザIDの一覧を取得し、それをもとにユーザ一覧を検索する方法で実装を行う。
AffiliationRepositoryクラスでは、Spring Dataのメソッド命名規約に従い、findByAffiliationpkGroupIdメソッドを作成する。
package org.debugroom.sample.cassandra.pattern2.domain.repository;
// omit
public interface AffiliationRepository extends CrudRepository<Affiliation, AffiliationPK>{
public List<Affiliation> findByAffiliationpkGroupId(Long groupId);
//omit
}
Note
エンティティクラスの変数名に合わせてメソッドのキャメルケースを決定すること。
サービス実装クラスでは、グループIDをキーに取得した所属データから、ユーザIDの一覧を作成し、IN句を使用した検索を実行する。
package org.debugroom.sample.cassandra.pattern2.domain.service;
// omit import statements.
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
UserRepository userRepository;
@Override
public List<User> getUsersByGroupId(Long groupId) {
List<Affiliation> affiliations =
affiliationRepository.findByAffiliationpkGroupId(groupId);
List<Long> userIds = new ArrayList<Long>();
for(Affiliation affiliation : affiliations){
userIds.add(affiliation.getAffiliationpk().getUserId());
}
List<User> users = userRepository.findByUserIdIn(userIds);
return users;
}
IN句を使用したCQLの実行のために、以下の通り、UserRepositoryクラスに、Spring Dataのメソッド命名規約に基づき、findByUserIdIn(List<Long> userIds)メソッドを作成する。
package org.debugroom.sample.cassandra.pattern2.domain.repository;
import org.springframework.data.cassandra.repository.Query;
import org.springframework.data.repository.CrudRepository;
import java.util.List;
import org.debugroom.sample.cassandra.pattern2.domain.entity.User;
public interface UserRepository extends CrudRepository<User, Long>, UserRepositoryCustom{
// omit
public List<User> findByUserIdIn(List<Long> userIds);
}
指定したグループに所属しない全てのユーザ一覧を取得する¶
指定したグループに所属するユーザIDの一覧を取得し、全ユーザデータから当該データを除外する方式で実装する。 サービス実装クラスでは、前ユースケース「指定したグループに所属するすべてのユーザ一覧を取得する」と同様、findByAffiliationpkGroupId()メソッドを使って、Affiliationテーブルから指定されたグループIDに属する所属データを取得したのち、Map形式で取得したユーザ一覧で、キーをとなるユーザIDを指定して除外する。
package org.debugroom.sample.cassandra.pattern2.domain.service;
// omit import statements.
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
UserRepository userRepository;
@Override
public List<User> getNotUsersByGroupId(Long groupId) {
List<Affiliation> affiliations =
affiliationRepository.findByAffiliationpkGroupId(groupId);
Map<Long, User> userMap = userRepository.findAllForMap();
for(Affiliation affiliation : affiliations){
userMap.remove(affiliation.getAffiliationpk().getUserId());
}
return new ArrayList<User>(userMap.values());
}
上記では、Map形式でユーザを取得するため、パターン1のユースケース「特定の郵便番号を持たないユーザ一覧を取得する」と同様に、カスタムRepositoryインターフェースを作成し、ResutSetExtractorを利用して実装する。
package org.debugroom.sample.cassandra.pattern2.domain.repository;
import java.util.Map;
import java.util.List;
import org.debugroom.sample.cassandra.pattern2.domain.entity.User;
public interface UserRepositoryCustom {
//omit
public Map<Long, User> findAllForMap();
}
実装クラスは、以下の通り、UserMapExtractorクラスを指定してクエリ実行する。
package org.debugroom.sample.cassandra.pattern2.domain.repository.impl;
import java.util.List;
import java.util.Map;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.data.cassandra.core.CassandraAdminOperations;
import org.springframework.data.cassandra.core.CassandraOperations;
import org.springframework.data.repository.NoRepositoryBean;
import com.datastax.driver.core.querybuilder.QueryBuilder;
import com.datastax.driver.core.querybuilder.Select;
import org.debugroom.sample.cassandra.pattern2.domain.entity.User;
import org.debugroom.sample.cassandra.pattern2.domain.repository.UserRepositoryCustom;
@NoRepositoryBean
public class UserRepositoryImpl implements UserRepositoryCustom{
@Autowired
@Qualifier("cassandraTemplate")
CassandraOperations cassandraOperations;
@Override
public Map<Long, User> findAllForMap() {
Select select = QueryBuilder.select().from("users");
return cassandraOperations.query(select, new UserMapExtractor());
}
}
UserMapExtractorクラスの実装は以下の通りである。
package org.debugroom.sample.cassandra.pattern2.domain.repository.impl;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.debugroom.sample.cassandra.pattern2.domain.entity.Address;
import org.debugroom.sample.cassandra.pattern2.domain.entity.Credential;
import org.debugroom.sample.cassandra.pattern2.domain.entity.Email;
import org.debugroom.sample.cassandra.pattern2.domain.entity.User;
import org.springframework.cassandra.core.ResultSetExtractor;
import org.springframework.dao.DataAccessException;
import com.datastax.driver.core.ResultSet;
import com.datastax.driver.core.Row;
import com.datastax.driver.core.UDTValue;
import com.datastax.driver.core.exceptions.DriverException;
public class UserMapExtractor implements ResultSetExtractor<Map<Long, User>>{
@SuppressWarnings("unchecked")
@Override
public Map<Long, User> extractData(ResultSet resultSet)
throws DriverException, DataAccessException {
Map<Long, User> userMap = new HashMap<Long, User>();
while(resultSet.iterator().hasNext()){
Row row = resultSet.one();
UDTValue address = row.getUDTValue("address");
List<Email> emails = new ArrayList<Email>();
List<Credential> credentials = new ArrayList<Credential>();
Long userId = row.getLong("user_id");
User user = User.builder()
.userId(userId)
.userName(row.getString("user_name"))
.isEnabled(row.getBool("is_enabled"))
.isLocked(row.getBool("is_locked"))
.isAdmin(row.getBool("is_admin"))
.emails(emails)
.credentials(credentials)
.build();
if(address != null){
user.setAddress(Address.builder()
.zipCd(address.getString("zip_cd"))
.address(address.getString("address"))
.ver(address.getInt("ver"))
.lastUpdatedDate(row.getTimestamp("last_updated_date"))
.build());
}
for(UDTValue udtValue : (List<UDTValue>)row.getObject("emails")){
emails.add(Email.builder()
.email(udtValue.getString("email"))
.ver(udtValue.getInt("ver"))
.lastUpdatedDate(udtValue.getTimestamp("last_updated_date"))
.build());
}
for(UDTValue udtValue : (List<UDTValue>)row.getObject("credentials")){
credentials.add(Credential.builder()
.credentialType(udtValue.getString("credential_type"))
.credentialKey(udtValue.getString("credential_key"))
.expiredDate(udtValue.getTimestamp("expired_date"))
.ver(udtValue.getInt("ver"))
.lastUpdatedDate(udtValue.getTimestamp("last_updated_date"))
.build());
}
userMap.put(userId, user);
}
return userMap;
}
}
指定したユーザを指定したグループに追加する¶
指定したユーザを指定したグループに追加することは、所属テーブルにデータを追加することとイコールであるため、AffiliationRepositoryでデータを追加するだけで良い。サービス実装クラスは、
package org.debugroom.sample.cassandra.pattern2.domain.service;
// omit import statements.
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
UserRepository userRepository;
@Override
public Group addUserToGroup(Long userId, Long groupId) {
Affiliation affiliation = Affiliation.builder()
.affiliationpk(AffiliationPK.builder()
.groupId(groupId)
.userId(userId)
.build())
.build();
affiliationRepository.save(affiliation);
return groupRepository.findOne(groupId);
}
指定したユーザをグループから除外する¶
前ユースケース「指定したユーザを指定したグループに追加する」と同様、所属テーブルにある該当のデータを削除すれば良い。サービス実装クラスは、
package org.debugroom.sample.cassandra.pattern2.domain.service;
// omit import statements.
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
UserRepository userRepository;
@Override
public Group deleteUserFromGroup(Long userId, Long groupId) {
Affiliation affiliation = affiliationRepository
.findOne(AffiliationPK.builder()
.groupId(groupId)
.userId(userId)
.build());
affiliationRepository.delete(affiliation);
return groupRepository.findOne(groupId);
}
指定したグループを削除し、ユーザが所属するグループの情報を更新する¶
当ユースケースの場合、削除対象のグループのIDをもつ所属テーブルのデータをすべて削除し、最後にグループを削除すれば良い。サービス内の複数のテーブルアクセスによるトランザクションは提供されないため、先に所属テーブルのデータを削除する形で実装する。
package org.debugroom.sample.cassandra.pattern2.domain.service;
// omit import statements.
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
UserRepository userRepository;
@Override
public Group deleteGroup(Long groupId) {
List<Affiliation> affiliations =
affiliationRepository.findByAffiliationpkGroupId(groupId);
for(Affiliation affiliation : affiliations){
affiliationRepository.delete(affiliation);
}
Group group = groupRepository.findOne(groupId);
groupRepository.delete(group);
return group;
}
指定されたユーザを削除し、グループのユーザ一覧を更新する¶
前ユースケース「指定したグループを削除し、ユーザが所属するグループの情報を更新する」と同様、削除対象のユーザIDを持つ所属テーブルのデータをすべて削除し、最後にユーザを削除すれば良い。
package org.debugroom.sample.cassandra.pattern2.domain.service;
// omit import statements.
@Service("sampleService")
public class SampleServiceImpl implements SampleService<User, Address, Email, Group>{
@Autowired
UserRepository userRepository;
@Override
public User deleteUser(Long userId) {
Map<Long, List<Long>> groupIdsMap = affiliationRepository.findGroupIdsMapByUserId();
List<Long> groupIds = groupIdsMap.get(userId);
for(Long groupId : groupIds){
affiliationRepository.delete(AffiliationPK.builder()
.groupId(groupId).userId(userId).build());
}
User user = userRepository.findOne(userId);
userRepository.delete(user);
return user;
}
データ整合性に問題が生じるケース¶
- サービス内でトランザクションが提供されないため、異なるテーブルへの更新処理は何らかのエラーが発生した場合、業務的なデータ論理性が保証されない場合が発生する。こうした場合、運用対処するか、補償トランザクションによるデータの整合性(エラーが発生した場合リトライ処理を行うよう実装すること)を考える必要がある。
非正規化によるデータ分散による不整合¶
- 非正規化された場合、複数のテーブルにデータが存在するため、データ更新の回数が増え、エラー発生頻度が高まり、データ整合性に問題が発生するリスクが高まる。同様に、運用対処するか、補償トランザクションによるデータの整合性(エラーが発生した場合、リトライ処理を行うよう実装すること)を考える必要がある。
レプリケーション間のデータ不整合¶
Cassandraにおけるデータモデリングのポイント¶
検証の結果からポイントをまとめると以下の通りとなる。
| No | ポイント | 理由 |
|---|---|---|
| 1 | 1度のデータアクセスで関連エンティティの 情報も含めて(ユーザと住所など)取得したい場合は ユーザ定義型を使用する。 |
結合の概念がないので、テーブル定義した単位で データアクセスする必要があるため。 |
| 2 | あるテーブルに全件データアクセスする場合は No1と併用するのであれば、非正規化が必要 |
ユーザ定義型のデータには当然全件検索できないため |
| 3 | プライマリキー以外を検索キーに指定する場合、 マテリアライズドビューを作成するか、 セカンダリインデックスを作成するか、 CQLにallow filteringオプションを付与する 必要がある。ただし、性能劣化が予想されるため、 非正規化することも検討する。 |
ユーザ定義型のデータには当然全件検索できないため |
設計手順¶
- リレーショナルモデルの設計手順
- 概念データモデル・論理設計
- エンティティの抽出
- エンティティモデル定義
- 正規化
- ER図の作成
- ユースケース記述・処理設計
- サービスインターフェース設計
- ドメインインターフェース設計
- コンポーネント処理設計(クエリ設計)
- 物理設計
- テーブル定義
- インデックス定義
- ハードウェアサイジング
- ストレージ冗長化構成
- 物理配置設計
- Cassandraでの設計手順
- 概念データモデル・論理設計
- エンティティの抽出
- エンティティモデル定義
- ユースケース記述・処理設計
- サービスインターフェース設計
- ドメインインターフェース設計
- コンポーネント処理設計(クエリ設計)
- 物理設計
- テーブル定義
- インデックス定義
- 物理配置設計