 JSUG 勉強会
JSUG 勉強会
AWSで作るクラウドネイティブアプリケーションの基本とDevOps
2019.9.20
自己紹介

- 名前:川畑 光平
- 会社:(株)NTTデータ
- 今の仕事:プロジェクト支援(主にクラウド系)とR&D
- SNSはFacebookのみなので質問あればDMかメールで
- 長崎県出身
- 趣味:AP実装、料理、水泳、スノボ、DQウォーク←New!
- 学生の頃Appleでバイトしてました(iPodが流行った頃)
- 2019.2月に長男が誕生
- 2019 APN AWS Top Engineers & Ambassadors
- マイナビ「ITSearch+」で記事連載中

←私
←長男
本日のトピックス


その前に…
 How to use this slide
How to use this slide
- 黄色の文字はリンク
- ESCキーを押すとスライドのオーバービュー
- Altキー + マウスクリックで拡大ズーム
- J,K,M,Lキーでも遷移
- 幾つかのスライドは下に遷移
- “shift + ?”でショートカットキー一覧
※当スライドは 「reveal.js」 を使って、GitHub Pages上に作成
Agenda
- Backgroundと対象読者
- 記事オーバービュー
-
 クラウドネイティブアプリケーション
クラウドネイティブアプリケーション -
 DevOps
DevOps
-
- 各テーマのポイント・補足
- 今後の記事公開予定
Background
- Springのガイドラインは社内にもあったが、よく使われるAWSサービスの概要や使い方・設定方法などがドキュメントとして抜け落ちていた。
- ここ最近で支援したAWSプロジェクトでアプリケーション実装、R&D検証した内容を別のプロジェクトでも利用可能なよう汎用化
- 幾つかのテーマに関して、AWSパートナーソリューションアーキテクトとも議論
- 内容を全社向けにフィードバックしようとしたが、どうせなら社外に公開(マイナビへWeb記事として寄稿)※ドキュメントとしてはまとめることができたが、色々数えきれないトラブルシューティングがあって苦労したので、そういった情報は共有して、できる限り、同業エンジニアの労力を軽減したい想い。
 記事の対象読者
記事の対象読者
-
できるだけ学習コスト低く、AWSをベースとしたクラウドネイティブなアプリケーション開発のポイントを知りたい方。とはいえ、最低以下のような経験は必要。
- Java・SpringFrameworkを使ったことがある経験者
- Unix・LinuxなどのPOSIX系OS、Dockerコンテナを使ったことがある経験者
- MavenやGitといった開発ツールを使ったことがある経験者
- AWSのマネージドサービスを可能な限り活用して、できるだけ少数のリソース(OSSを活用するのはよいですが、そのためにEC2立てたり、ライセンス以外のコストも大きいのでそれを避けたい)で開発を行いたい方。
- クラウドネイティブな実装方法からマイクロサービス、CI/CD、基盤自動化まで一貫したストーリーでのベースの雛形が欲しい方。
- 各テーマを一部切り取って、構築・実装の参考にしたい方。
Article Overview
AWSクラウドでよく利用される基本的なサービスの構築方法や、SpringBootをベースとしてクラウド特有の特徴を活用したアプリケーションを実装する際の基本事項をまとめた連載記事
サーバレス編
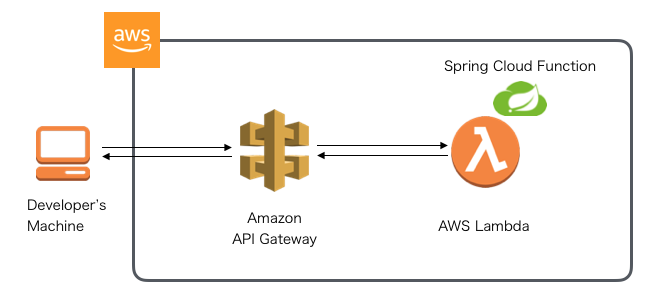
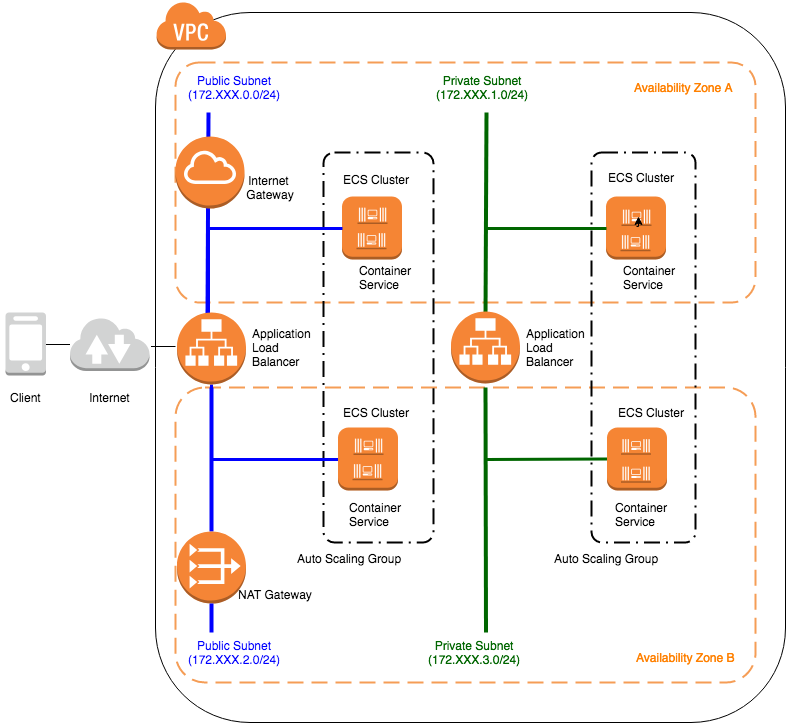
ECSコンテナ編
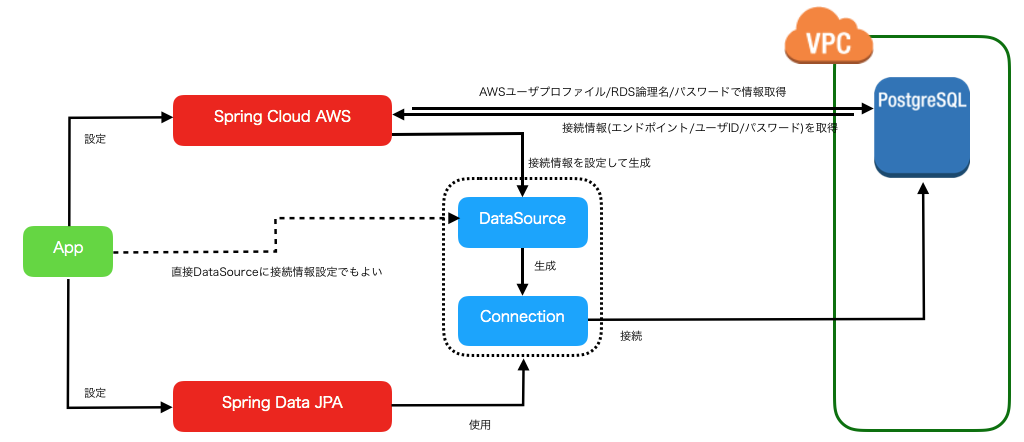
RDS(PostgreSQL)編
NoSQL編
NoSQL編
NoSQL編
S3編(今月から公開)
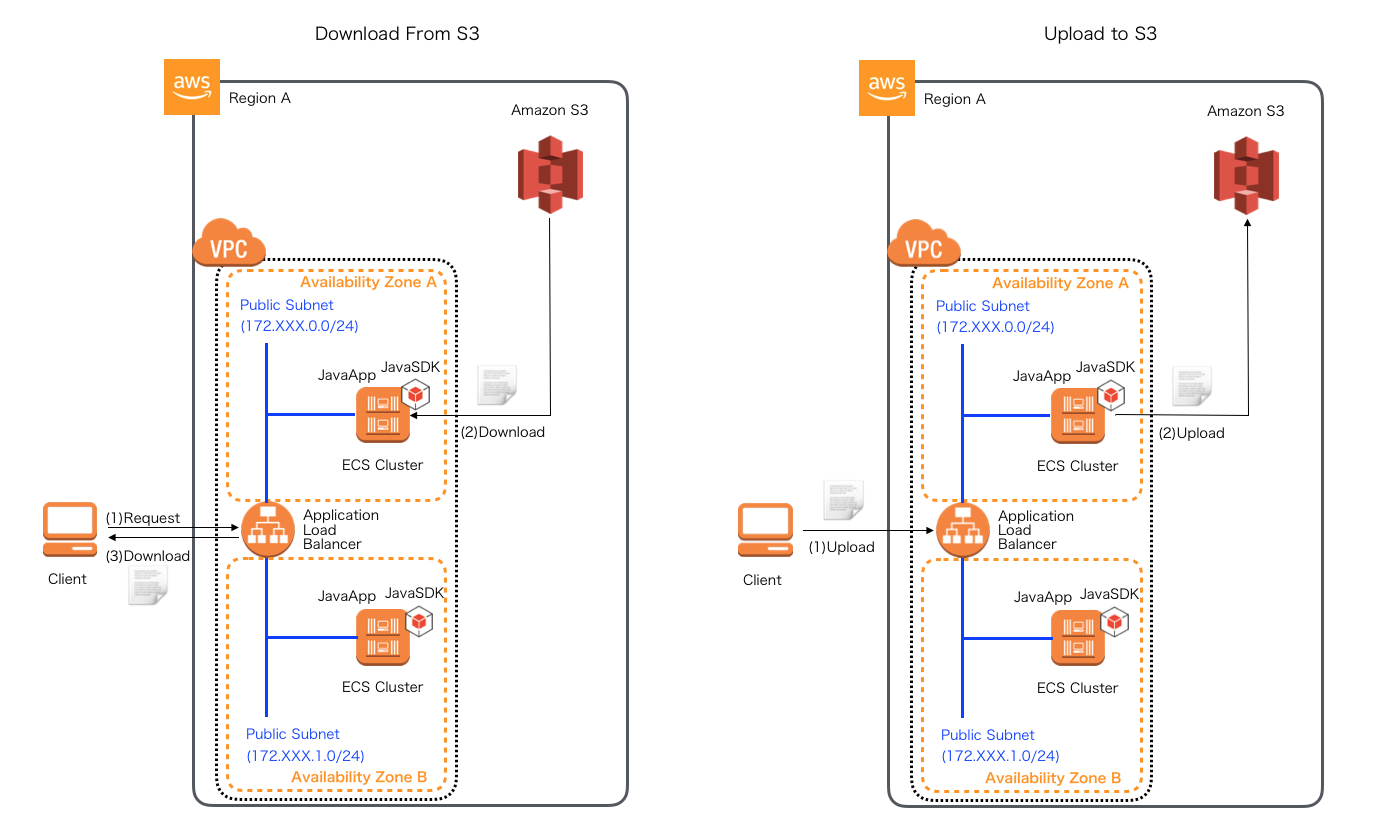
- (25) AmazonS3バケットの構築とアップロード
- (26) SpringCloudAWSを使ったファイルダウンロード・アップロード実装(設定)
- (27) SpringCloudAWSを使ったファイルダウンロード・アップロード実装(処理実装)
SQS編(来月から公開)
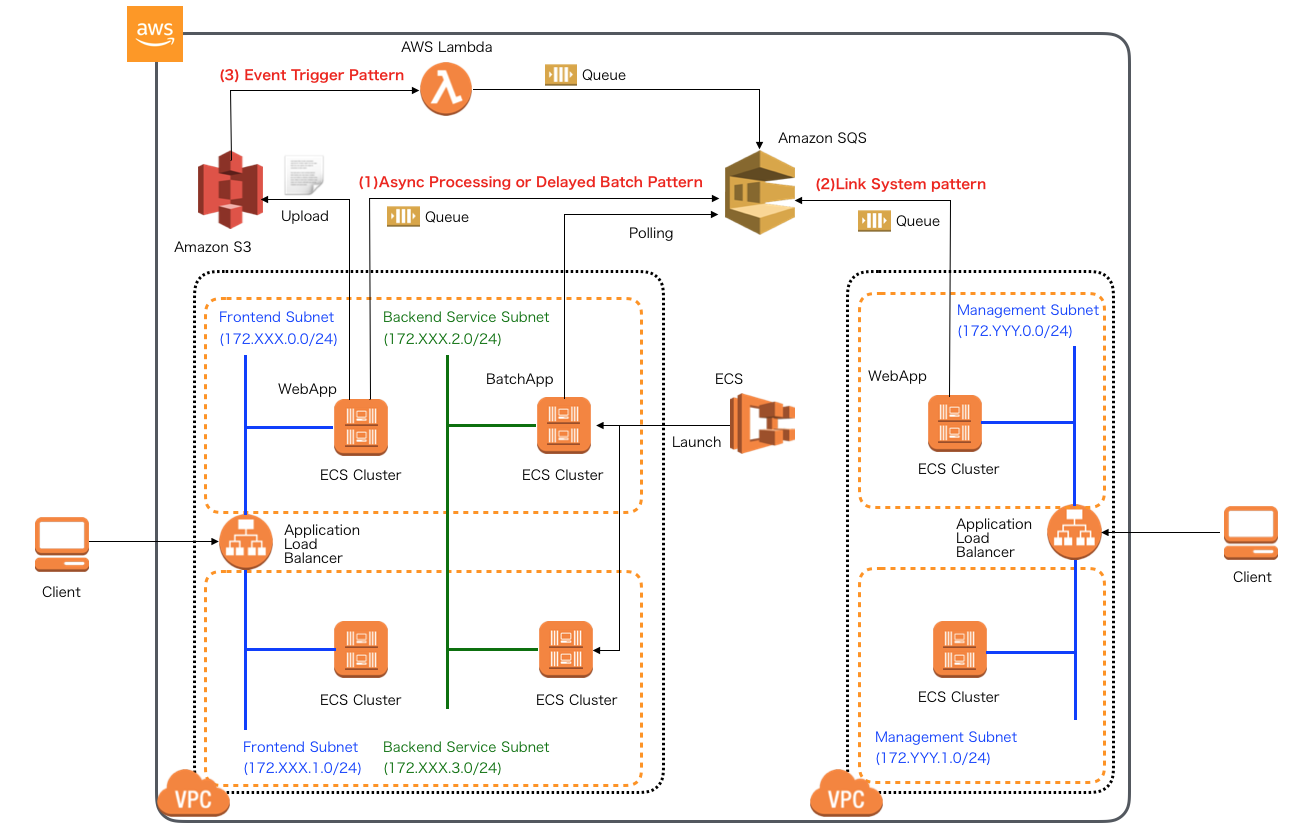
- SQS+SpringCloudAWSを使用したオンライン非同期処理パターン(Producer)
- ディレードバッチやクラウドサービスイベントトリガーパターン
- SQS+SpringCloudAWS+SpringBatch+ECSTaskScheduler(Consumer)
- 現在実装のみ公開
Article Overview
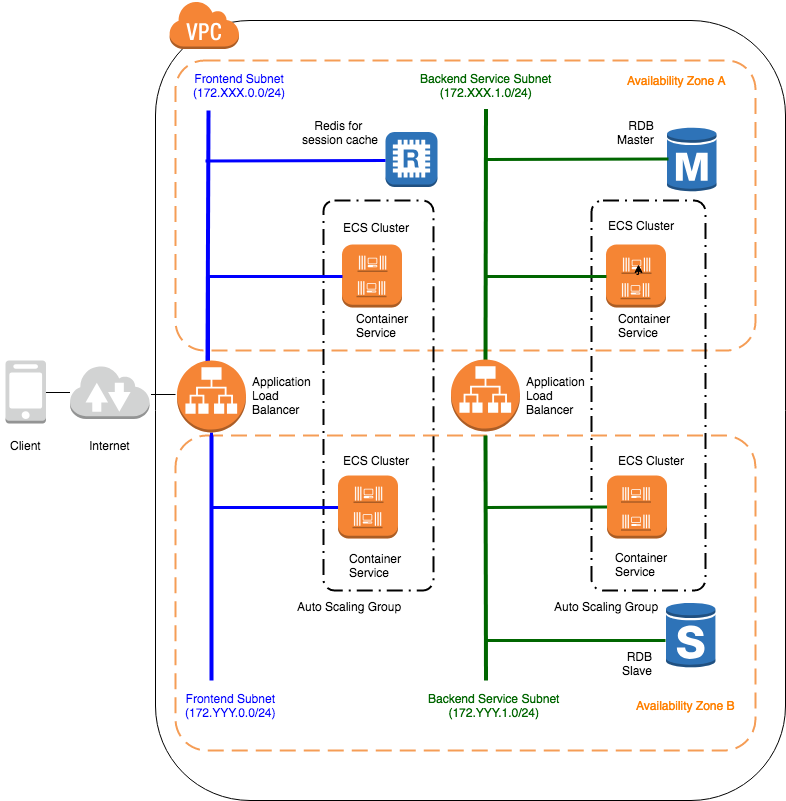
クラウドネイティブECSコンテナ編の環境でMSAアプリケーションを構築
CI - 静的チェックツール環境導入編 -
CI - SpringBootテストコード実装編 -
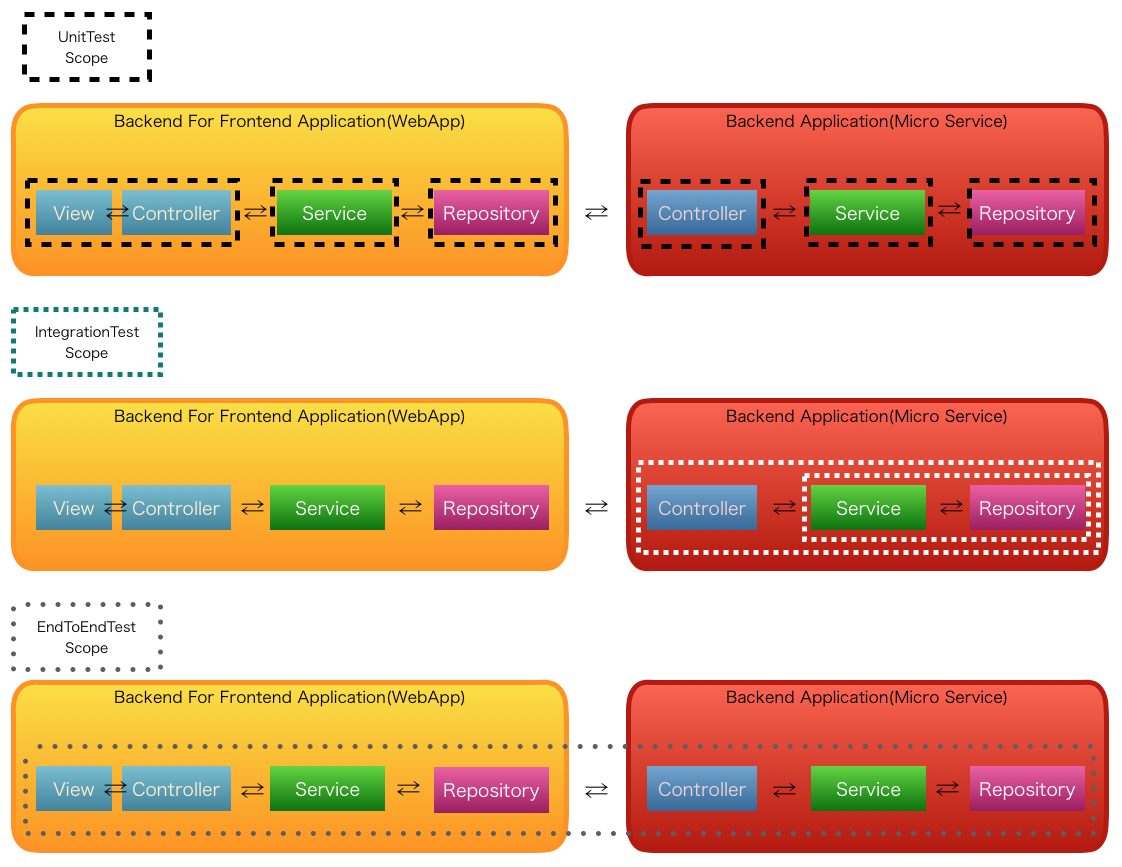
-
(5〜6)マイクロサービスにおける単体テストコード実装
- @DataJpaTestアノテーションの利用
- @SpringBootTestアノテーションの利用
- @WebMvcTestアノテーションの利用
-
(7)マイクロサービスにおける結合テストコード実装
- DBUnitの利用
- TestRestTemplateの利用
-
(8)マイクロサービスを呼び出す側の単体テストコード実装
- MockRestServiceServerの利用
- HTMLUnitの利用
-
(9)マイクロサービスを含むEnd2Endテストコード実装
- Seleniumの利用
CI - AWS CodeBuildによるCI実践編 -
CI - AWS CodeBuildによるCI実践編 -
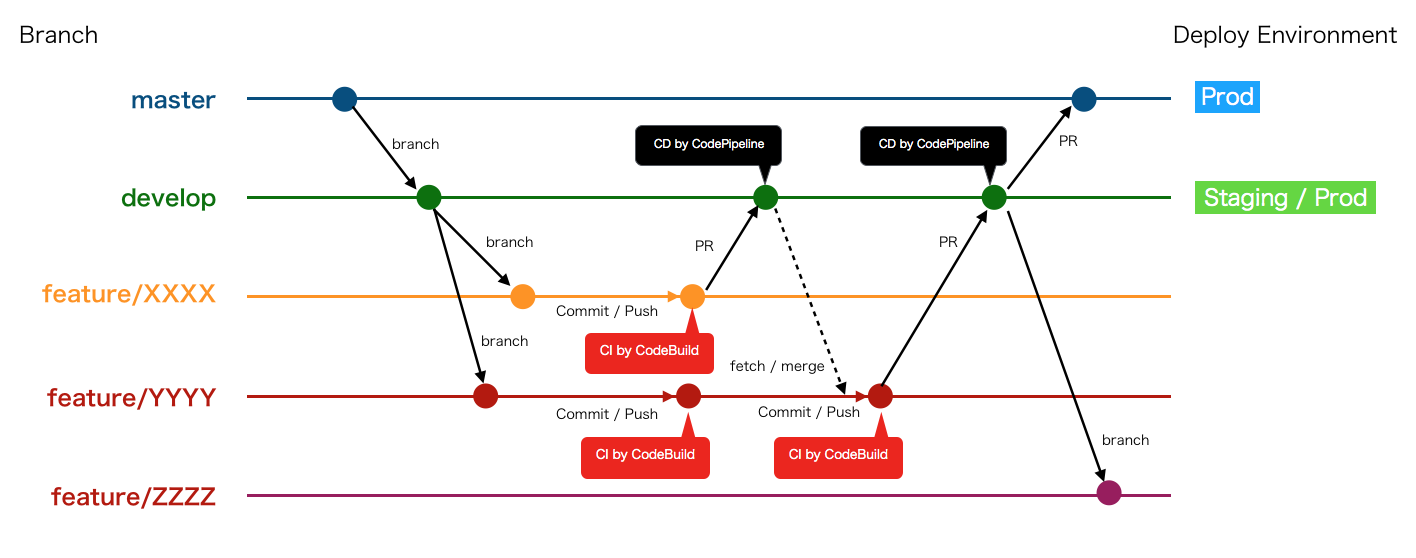
GitHubフローをベースにしたブランチ戦略
AWS CodePipelineによるCD実践編(今月から)
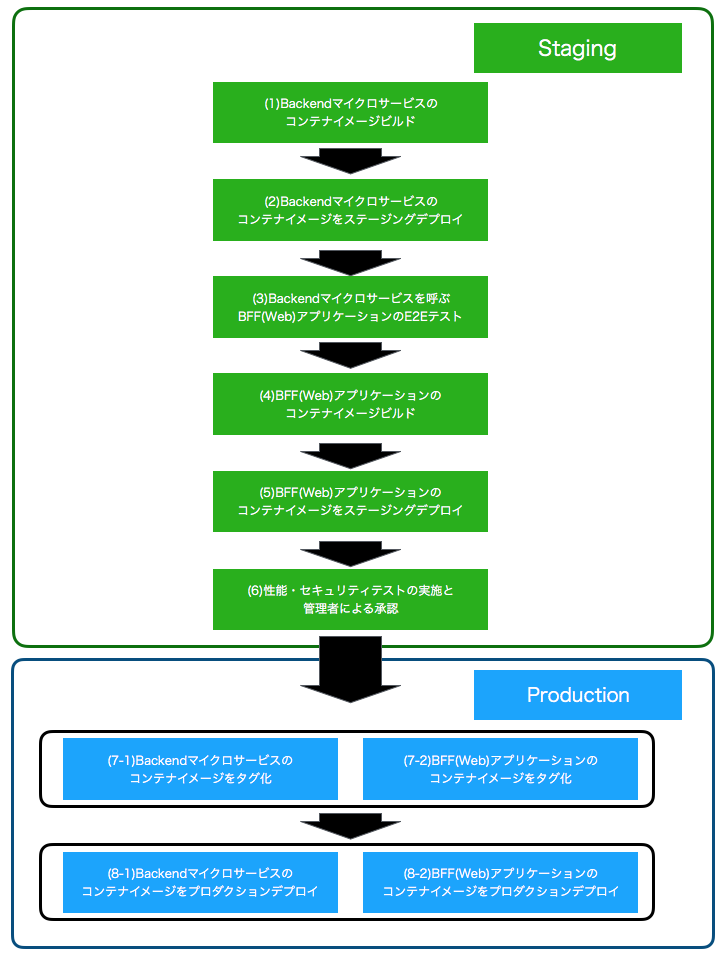
CD - AWS CodePipelineによるパイプライン1 -
Backendコンテナイメージの作成・プッシュ
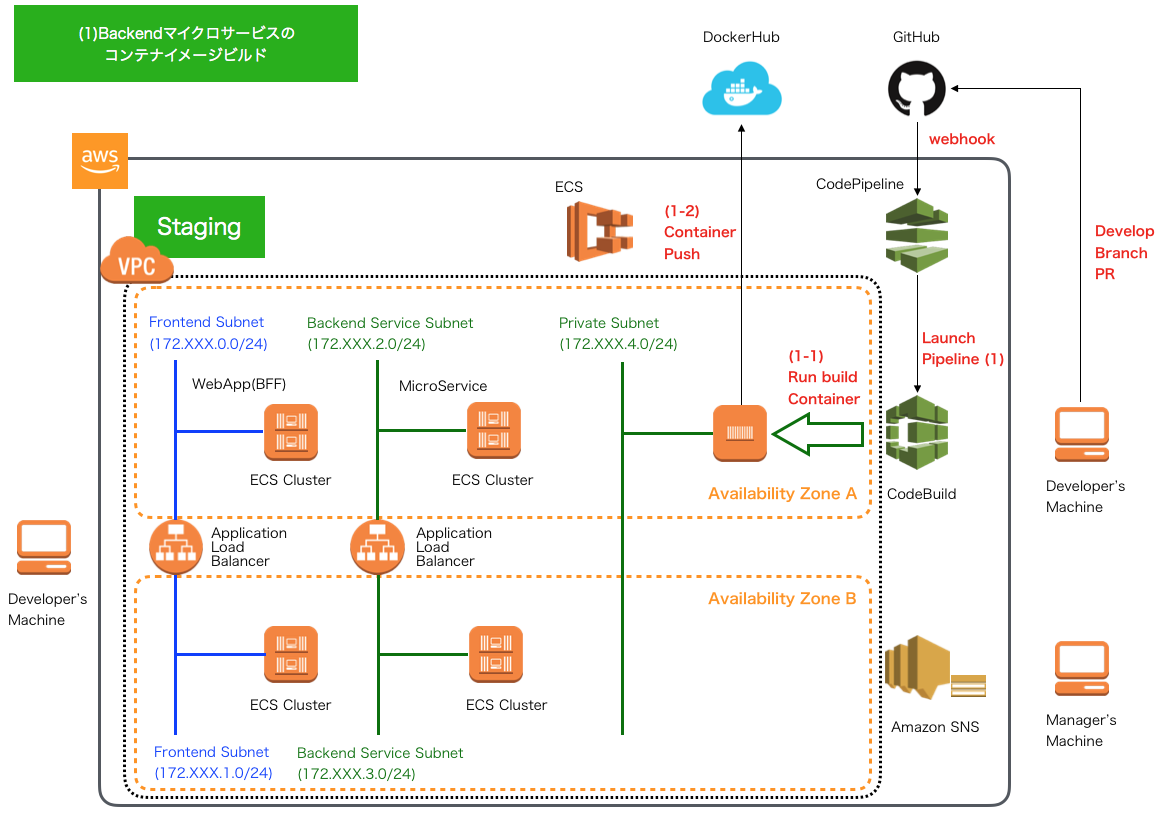
CD - AWS CodePipelineによるパイプライン2 -
ステージング環境へのBackendコンテナデプロイ
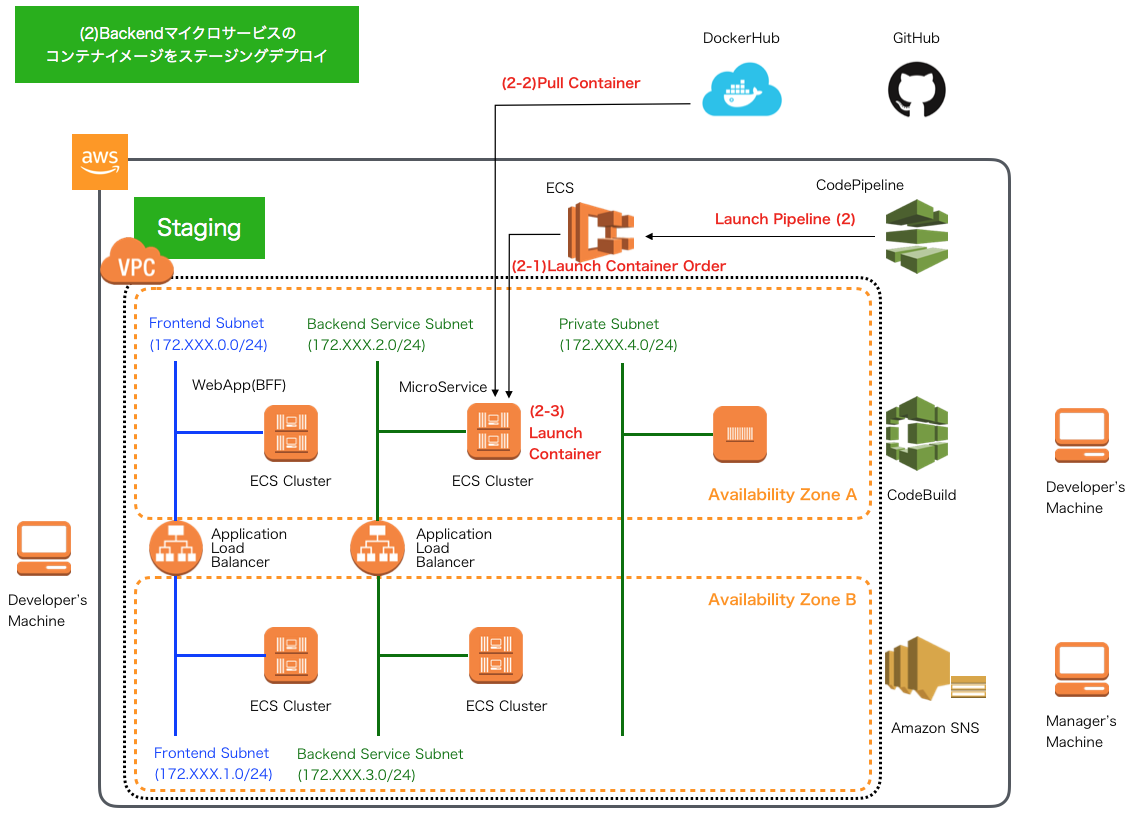
CD - AWS CodePipelineによるパイプライン3 -
WebアプリケーションでのE2Eテスト・コンテナイメージ作成
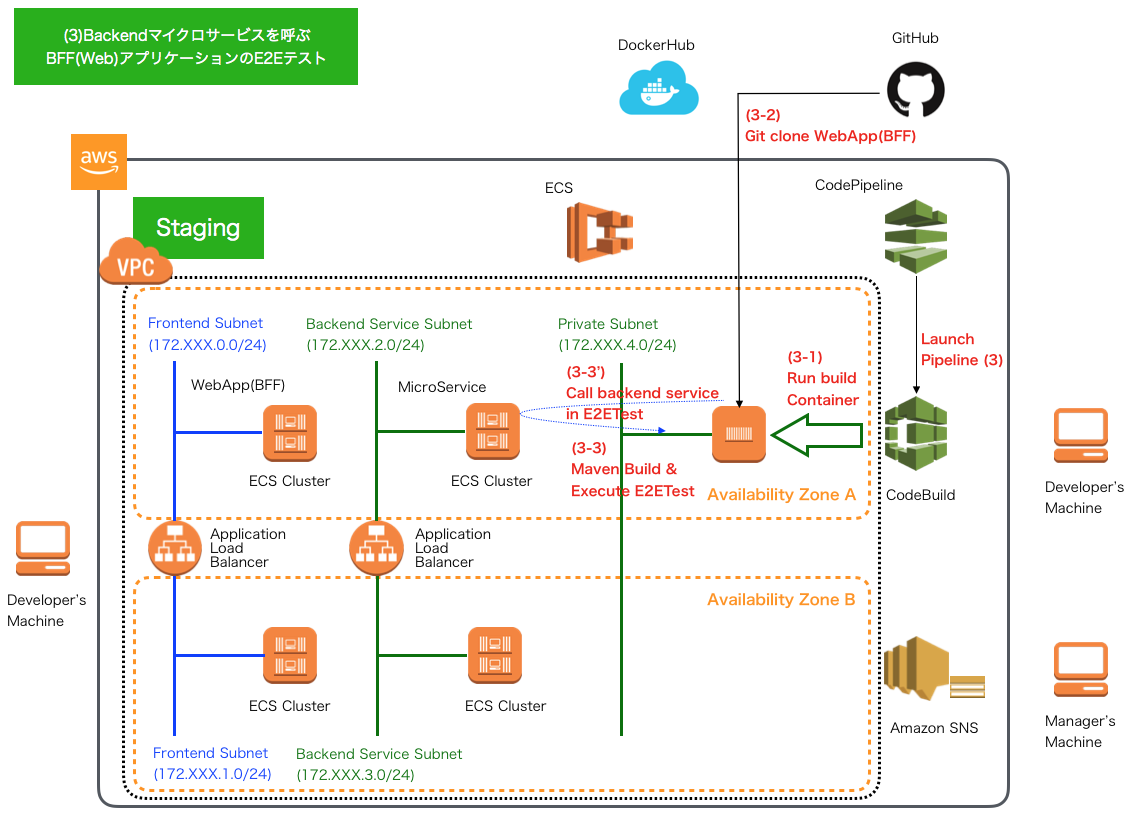
CD - AWS CodePipelineによるパイプライン4 -
Webアプリケーションのコンテナイメージのプッシュ
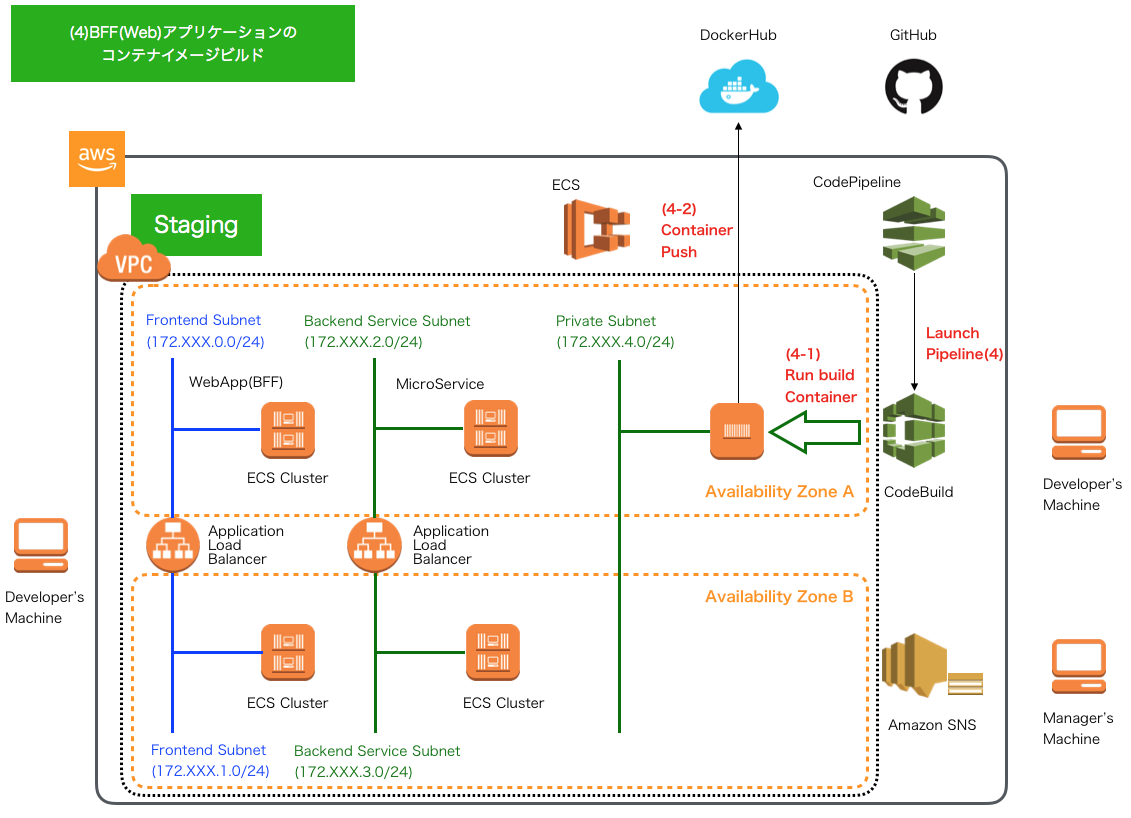
CD - AWS CodePipelineによるパイプライン5 -
ステージング環境へのWebアプリケーションのコンテナデプロイ
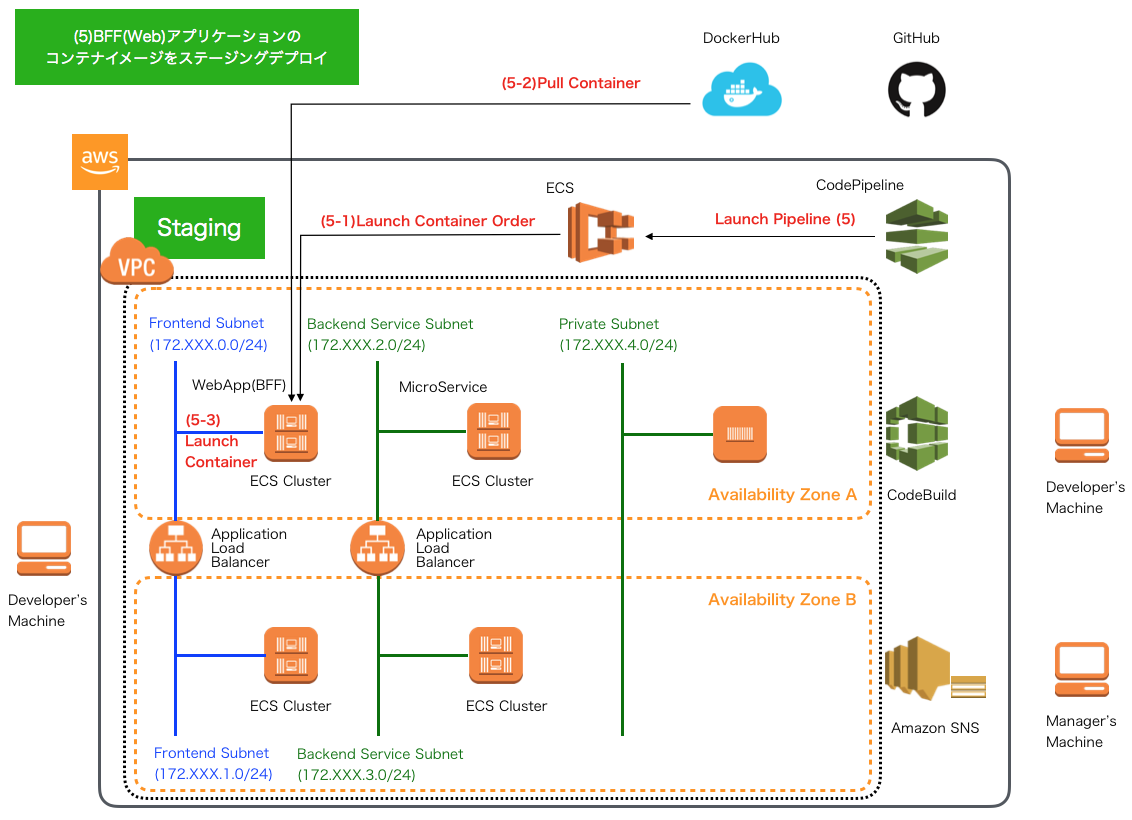
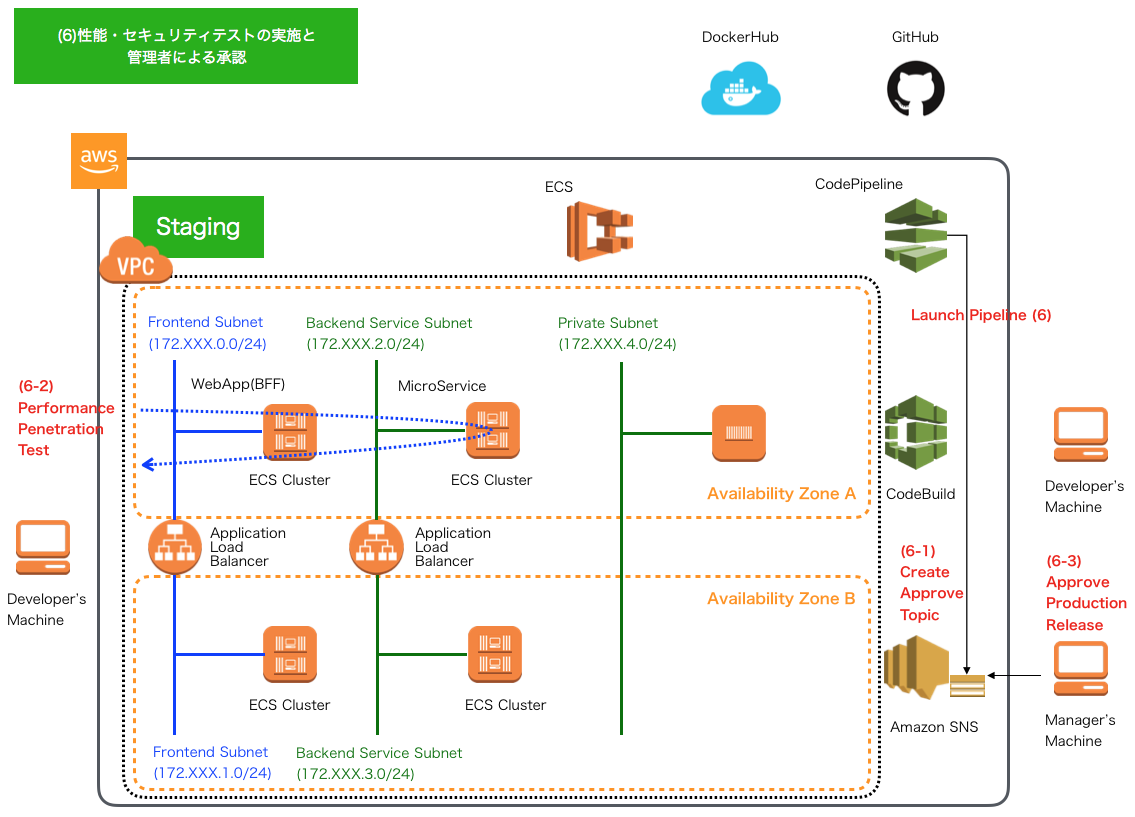
CD - AWS CodePipelineによるパイプライン6 -
ステージング環境でのその他テスト実行・管理者の承認プロセス
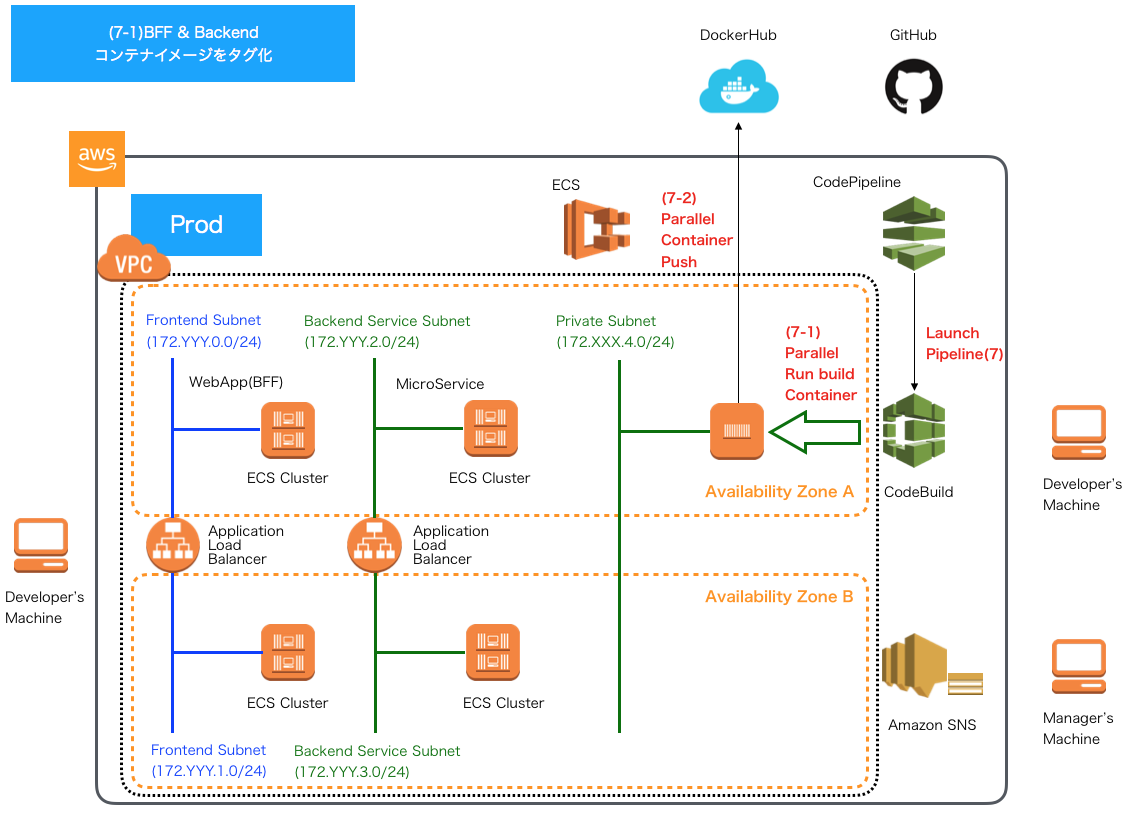
CD - AWS CodePipelineによるパイプライン7 -
Backend・Webアプリケーションのコンテナイメージの並行プッシュ
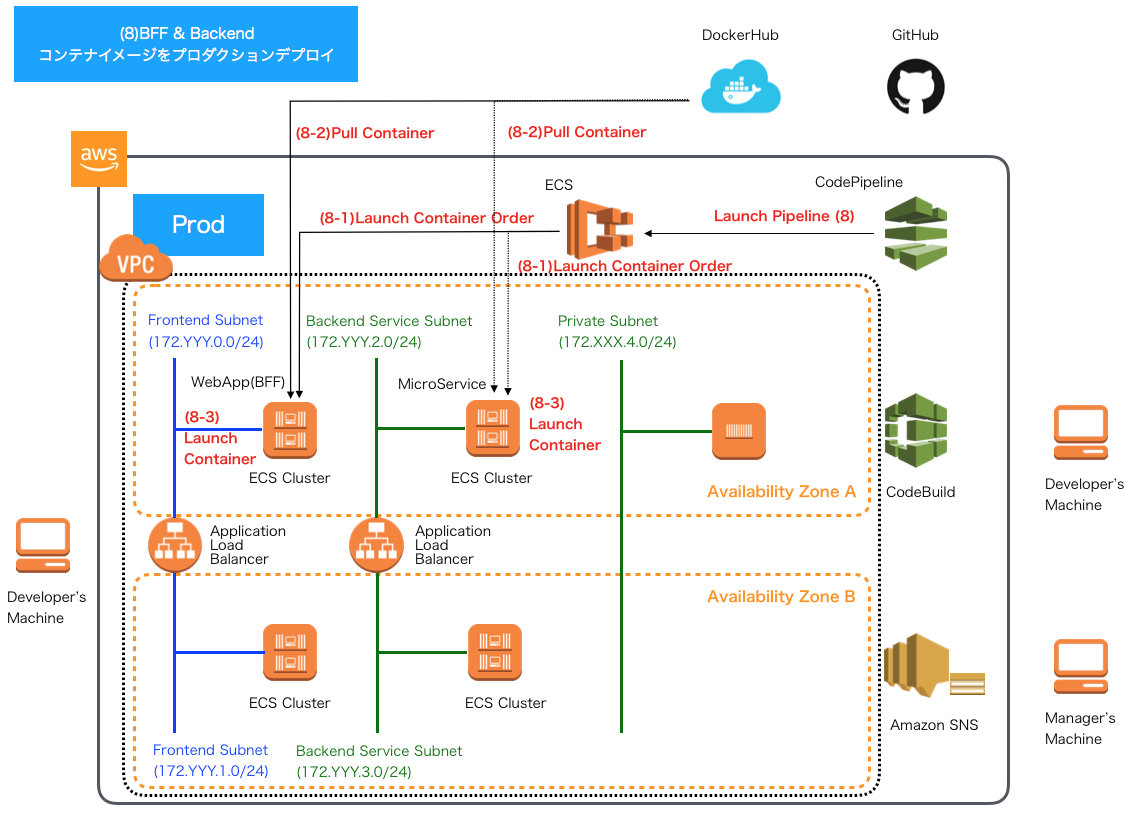
CD - AWS CodePipelineによるパイプライン8 -
プロダクション環境へのBackend・Webアプリケーションのコンテナ並行デプロイ
 各テーマのポイント・補足
各テーマのポイント・補足
![]() クラウドネイティブアプリケーションのポイント
クラウドネイティブアプリケーションのポイント
- サーバレス&コンテナアプリケーションの基本の使い方を押さえる
- サーバレス&コンテナアプリケーションを上手く組み合わせる
- RDB&NoSQLをユースケースに合わせて上手に使いこなす
- 共有ストレージをユースケースに合わせて上手に使いこなす
- キューをユースケースに合わせて上手に使いこなす
サーバレス編
[補足]どうなの?サーバーレス
- 画像加工やエンコードなどとにかくマシンリソースを使う処理の場合、パフォーマンス影響を気にしなくて良い
- コンテナアプリケーションにも組み込みが容易。S3ファイルアップロード、SQSキュー受信等のイベント後続処理でLambdaファンクション実行といった形が楽に実装できる
- SQSキュー、SNSへの連携、DynamoDBやRDSへのアクセスなどのLambdaでの実装はボイラープレートコードが乱立しがち。Spring Cloud Function + Spring Cloud AWS + Spring Data XXXと組み合わせればかなりスッキリかける
- エラー発生時の例外ハンドリング(ユーザへの通知やシステムメッセージどうするか)がいつも課題。同期的なハンドリングは複雑になりがちで難しく、デッドレターキューに投げつけるなど雑な対応しかできないのでは
- Lambdaファンクションの初回実行時、SpringのDIコンテナが数10秒の起動時間を要する。2回目以降、実行環境が再利用されるので以降の起動オーバーヘッドはほぼ無視して良いが、処理が行われない状態がある程度続く場合、環境が破棄されるので、随時即時性が必要なユースケースにマッチするかFit&Gapが必要
- デバッグやテストが大変。
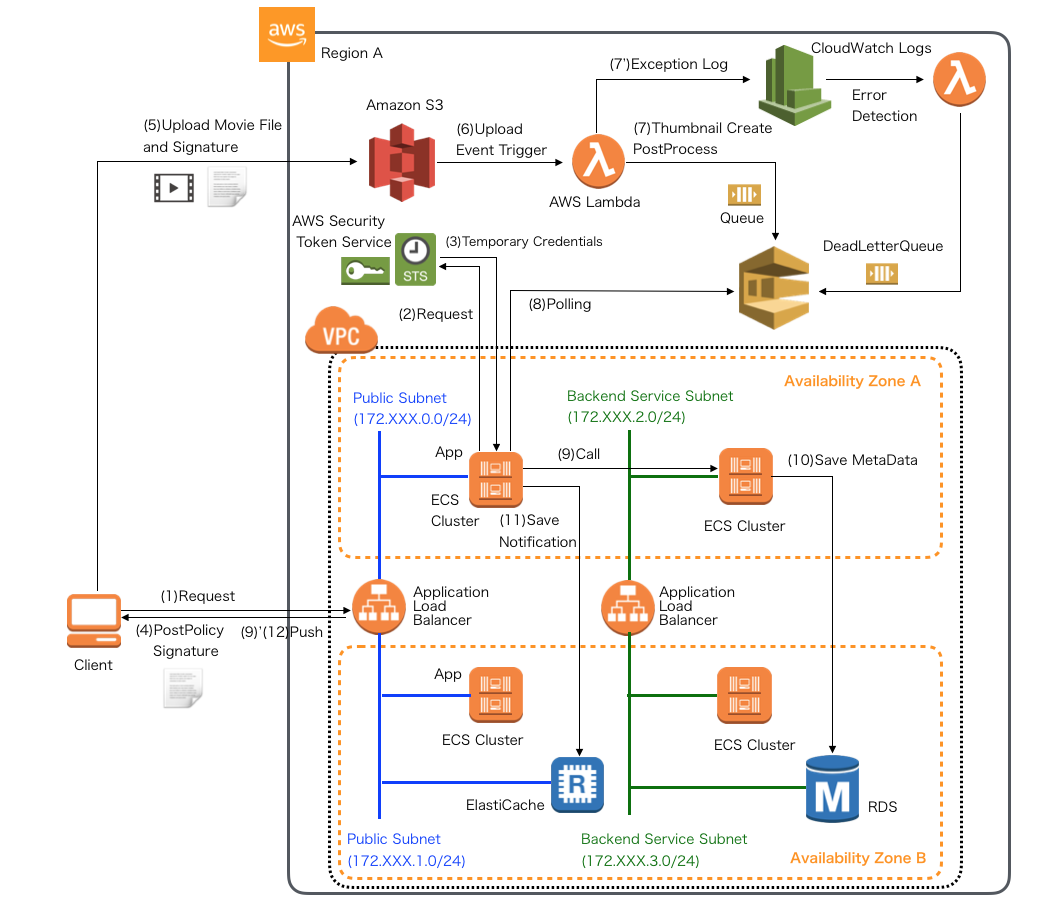
例外ハンドリングが大変な例(動画をアップしてサムネイルを作る処理)
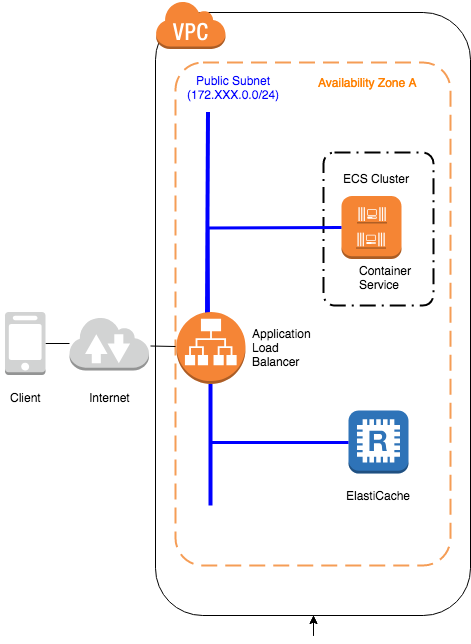
ECSコンテナ編
[補足]なぜこの構成にしたの?
A. 下記の案もありました。
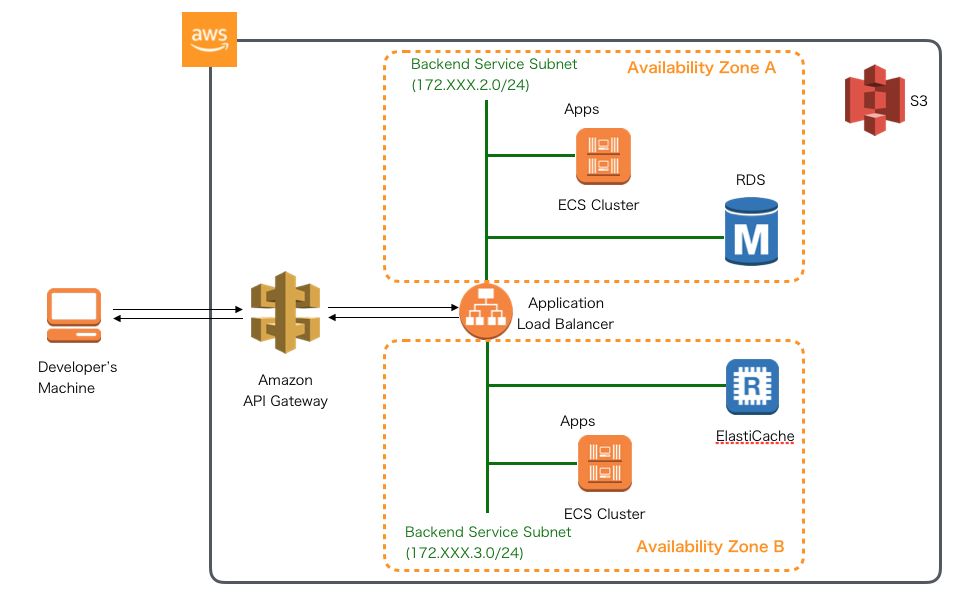
が、下記の理由によりやめました。
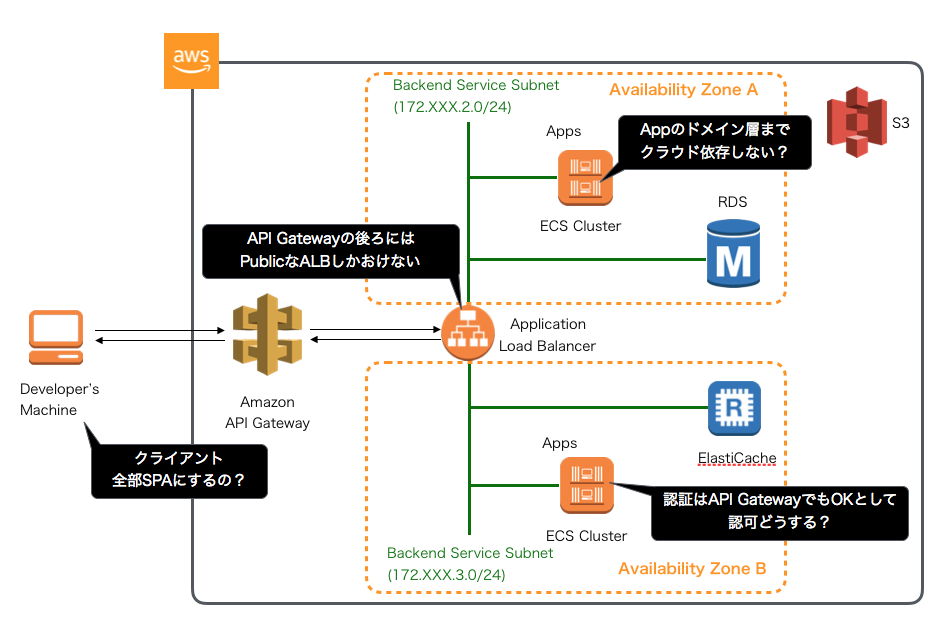
結局、この形にしました。しかし、この構成が唯一の正解というわけではありません。
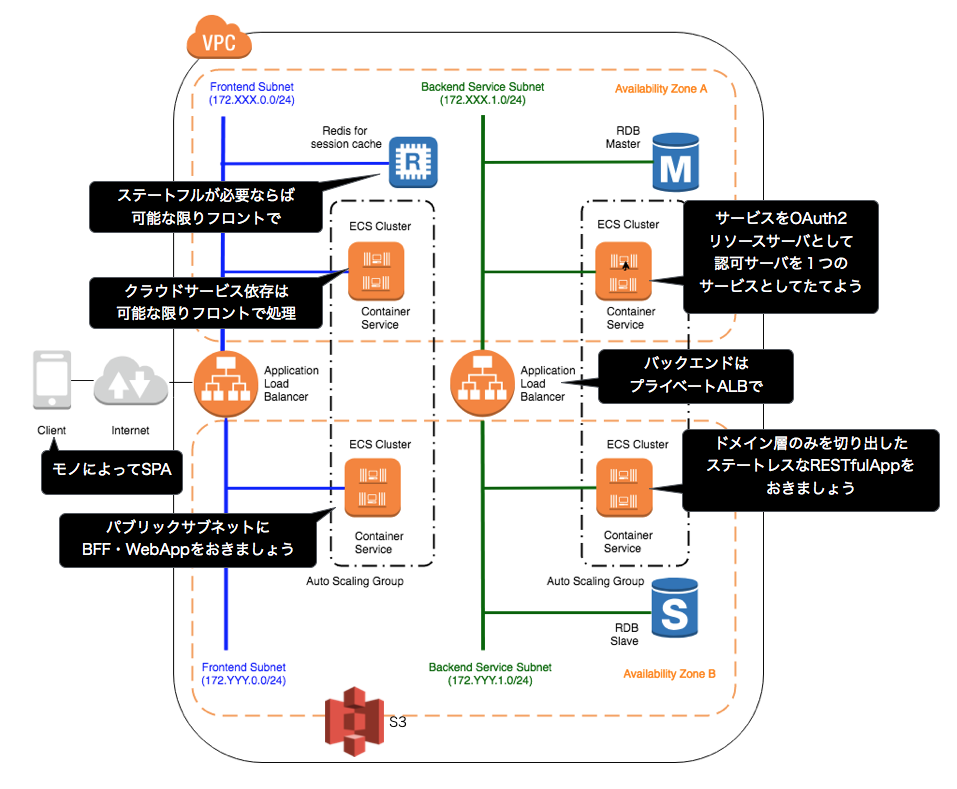
ただし、以下のようなメリットを得ることはできます。
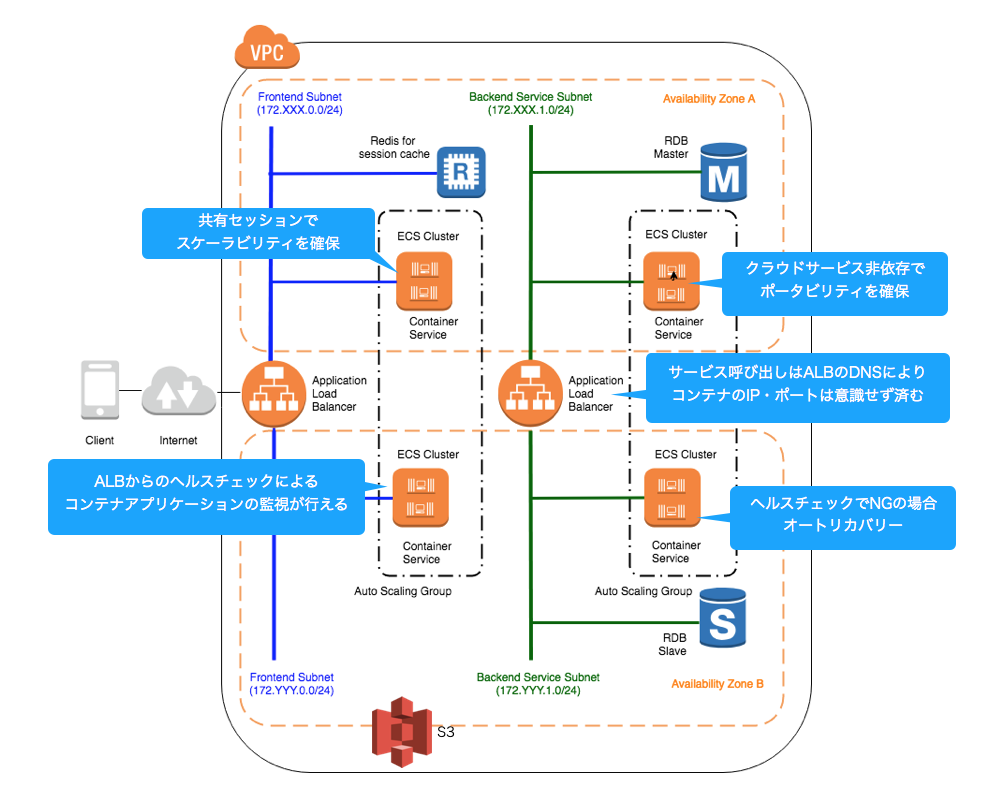
[補足]その他ツッコミ
A. ALBだとパスベースルーティング [http://service.com/xxxxxのxxxx] でコンテナごとにリクエストを振り分けられるのでALBにしてます。 AppMeshは最近出てきたサービスなのでまだ試してません。将来的に検証する予定です。 サービスの切り出し単位によっても異なりますし、将来的な意味でも、現在の構成が唯一の正解ではないと思います。
[補足]その他ツッコミ
A. EKSが東京リージョンにリリースする前に検討していたので、いったん見送りました。それにECSが想定していた以上にオーケストレーションとして優秀だったこと(ALBとECSコンテナ間のポートマッピングやセキュリティ制御、Dockerコンテナの再利用性など不足が感じられなかったこと)や、また、後述するCodeBuild、CodePipelineとのCI、CD、他のAWSサービス連携は現在もEKSよりECSの方が一日の長があります。ただし、Kubernetesの使用はベンダロックインの観点から採用頻度が高いので今後検証する予定です。場合によっては、フロントやバックエンドをEKS構成に置き換えてもよい(というか置き換えが可能であるべき)と思います。
RDS編
[補足]Spring Cloud AWS必要?
A. 設定が簡潔なのがメリット。環境変数はSystemsManagerから取得し、セキュリティも向上。
設定クラス
@Configuration
@EnableRdsInstance(
dbInstanceIdentifier = "${rds.identifier}",
password ="${rds.password}",
readReplicaSupport = false)
public class RdsConfig {
}
rds:
identifier: ${RDS_IDENTIFIER}
password: ${RDS_PASSWORD}
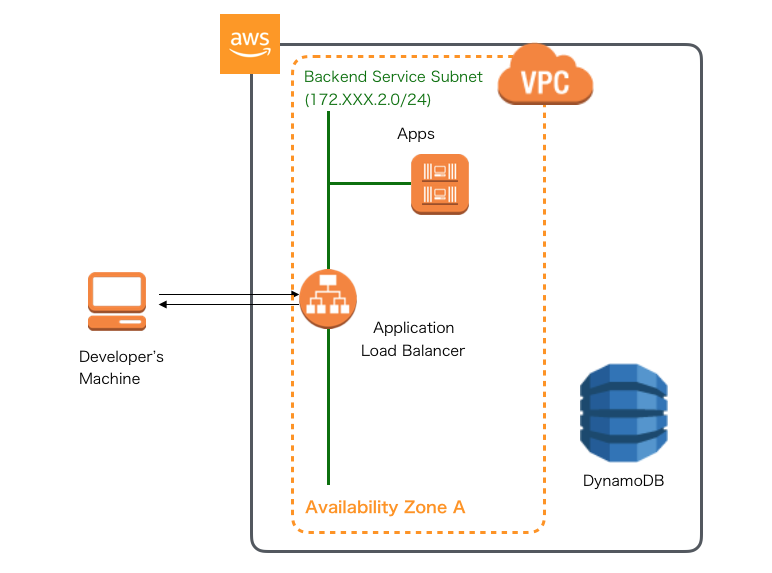
NoSQL編
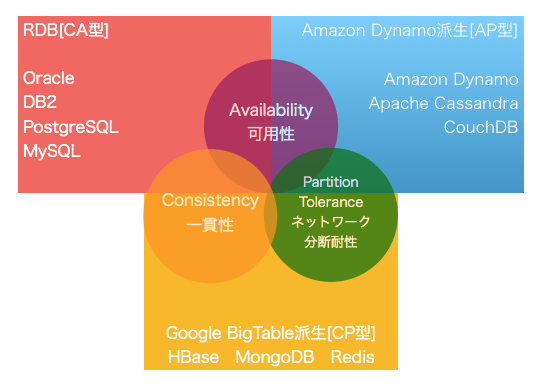
[ポイント]各データベースに適したユースケースやデータ特性
NoSQLは色々種類や特徴があるが、ユースケースやデータ特性に適したものを選択すべき。
| タイプ | ユースケース/データ特性 | 使いどころ |
|---|---|---|
| CA型 | 複雑な条件 | 集合関数や射影/結合/副問い合わせ等 |
| 厳密なトランザクション/整合性 | 多額の決済データ、人命に関わるようなデータ | |
| 高負荷アップデート | 正規化を前提としたデータモデル | |
| CP型 | キャッシュ | 一部が利用できなくても大きな問題はない |
| 高速バッチ処理 | シャーディングによる高速処理 | |
| AP型 | スケーラブルアプリケーション | ノードの追加を動的に行いたい |
| マルチリージョン | グローバルなデータセンタ間のデータ共有 | |
| 大量の書き込み | 単一障害点がないため、IoTセンサーデータなど大量書き込み |
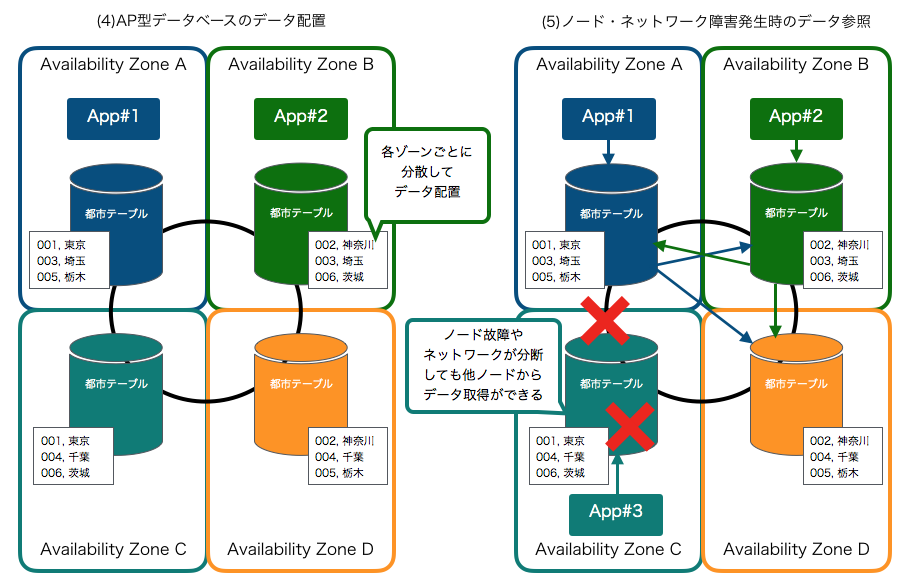
クラウドネイティブなAP型データベース
- AWSで作るクラウドネイティブアプリケーション(発展編)で解説予定
- ただ、当面先になるのでポイントだけ列挙
- 1:1や1:Nのような関係のデータモデルだとRDBと同じような形でもそんなに問題はない
- ただし、キー以外の検索ができないので、それ以外の項目で検索をかける場合はインデックスを作っておく
- N:Nの関連になるようなデータモデルはRDBと同じように関連実体(学生エンティティと講義エンティティの間にある受講のような実体でキーだけのインデックステーブル)を作っておくとうまくいくケースも多い
- テーブルのJOINは当然できないので、アプリ側でデータを取ってきてから加工する手法を使う
SpringだとResultSetExtractorを拡張してMap形式で結合したいキーとデータをマッピングするのがポイント - 設計はまずデータアクセスのユースケースを洗い出すこと(それから適したデータモデルを考える)。
- 参照は検索キーを注意していれば良いが、非正規化されたデータだと更新処理がしんどい(現実的でない)場合があるので、従来通りRDBを使う(あるいは併用する)ことも検討する
- 大量書き込み時はプライマリキーにUUIDや乱数などで書き込むノードを分散させる。
- ホットデータとコールドデータでテーブルを分けること
CP型のElastiCache(Redis)
ElastiCache Multi-AZ VS Redis Sentinel
[補足]マルチAZでのフェイルオーバー
| ElastiCache Multi-AZ | Redis Sentinel | |
|---|---|---|
| Spring Cloud AWS Support | ○ | × |
| Spring Data Redis Support | × | ○ |
| ダウンタイム | 数分※ | 即時 |
| AWSマネージド | ○ | × |
| エンドポイント変更 | なし | あり |
S3編
[ポイント]認証キーの取り扱い方 - よくない例 - ![]()
@Configuration
public class S3Config {
@Value("${cloud.aws.credentials.accessKey}")
private String accessKey;
@Value("${cloud.aws.credentials.secretKey}")
private String secretKey;
@Value("${cloud.aws.region.static}")
private String region;
@Bean
public BasicAWSCredentials basicAWSCredentials() {
return new BasicAWSCredentials(accessKey, secretKey);
}
@Bean
public AmazonS3 amazonS3Client(AWSCredentials awsCredentials) {
return AmazonS3ClientBuilder.standard().withRegion(Regions.fromName(region)).build();
}
}
cloud.aws.credentials.accessKey=XXXXXXXXXXXXXX
cloud.aws.credentials.secretKey=YYYYYYYYYYYYYY
cloud.aws.region.static=ap-northeast-1
cloud.aws.region.auto=false
[ポイント]認証キーの取り扱い方 - ダメじゃないけどイマイチな例 - ![]()
@Configuration
public class S3Config {
@Value("${cloud.aws.credentials.accessKey}")
private String accessKey;
@Value("${cloud.aws.credentials.secretKey}")
private String secretKey;
@Value("${cloud.aws.region.static}")
private String region;
@Bean
public BasicAWSCredentials basicAWSCredentials() {
return new BasicAWSCredentials(accessKey, secretKey);
}
@Bean
public AmazonS3 amazonS3Client(AWSCredentials awsCredentials) {
return AmazonS3ClientBuilder.standard().withRegion(Regions.fromName(region)).build();
}
}
cloud:
aws:
credentials:
accessKey: ${AWS_ACCESS_KEY_ID}
secretKey: ${AWS_SECRET_ACCESS_KEY}
[ポイント]認証キーの取り扱い方 - よい例 - ![]()
@Configuration
public class S3Config {
@Bean
public AmazonS3 amazonS3(){
return AmazonS3ClientBuilder.standard().build();
}
}
- 開発環境では、~/.aws/credentialsに開発用のアクセスキーと秘密キーをおいておく。
- 本番環境ではEC2やECSコンテナにIAMロールを設定する。
- GitHubのパブリックレポジトリにプッシュしたら、キーを探索しているボットに直ちに奪取される
- キーの部分を環境変数に変えてやっている例も割と見かけるが、オススメのやり方ではない。
- 環境変数で開発環境や本番環境ごとにキーを替える想定だと思われるが、上記の設定クラスのコード中で、AmazonS3ClientBuilder.standard().build()で内部的に呼ばれるDefaultAWSCredentialsProviderChainでは、以下の順で認証情報を取得する※
- 環境変数AWS_ACCESS_KEY_IDとAWS_SECRET_ACCESS_KEY
- システムプロパティaws.accessKeyIdとaws.secretKey
- ユーザーのAWS認証情報ファイル(~/.aws/credentialsのこと)
- AWSインスタンスプロファイルの認証情報
- つまりあえてプロパティファイルに環境変数を設定する必要はそもそもない
- 本番環境は最後の「AWSインスタンスプロファイルの認証情報」でIAMロール経由で一時認証情報を取得することをAWSとして推奨している。
- 本番環境用のキーを払い出すことがそもそもNG。従って、本番環境のキーを環境変数で切り替えるやり方はオススメではない
- AWSインスタンスプロファイルの認証情報の詳細は Amazon EC2 の IAM ロールを参照のこと。
クラウド特有の実装:STSを使ったS3ダイレクトアップロード・ダウンロード
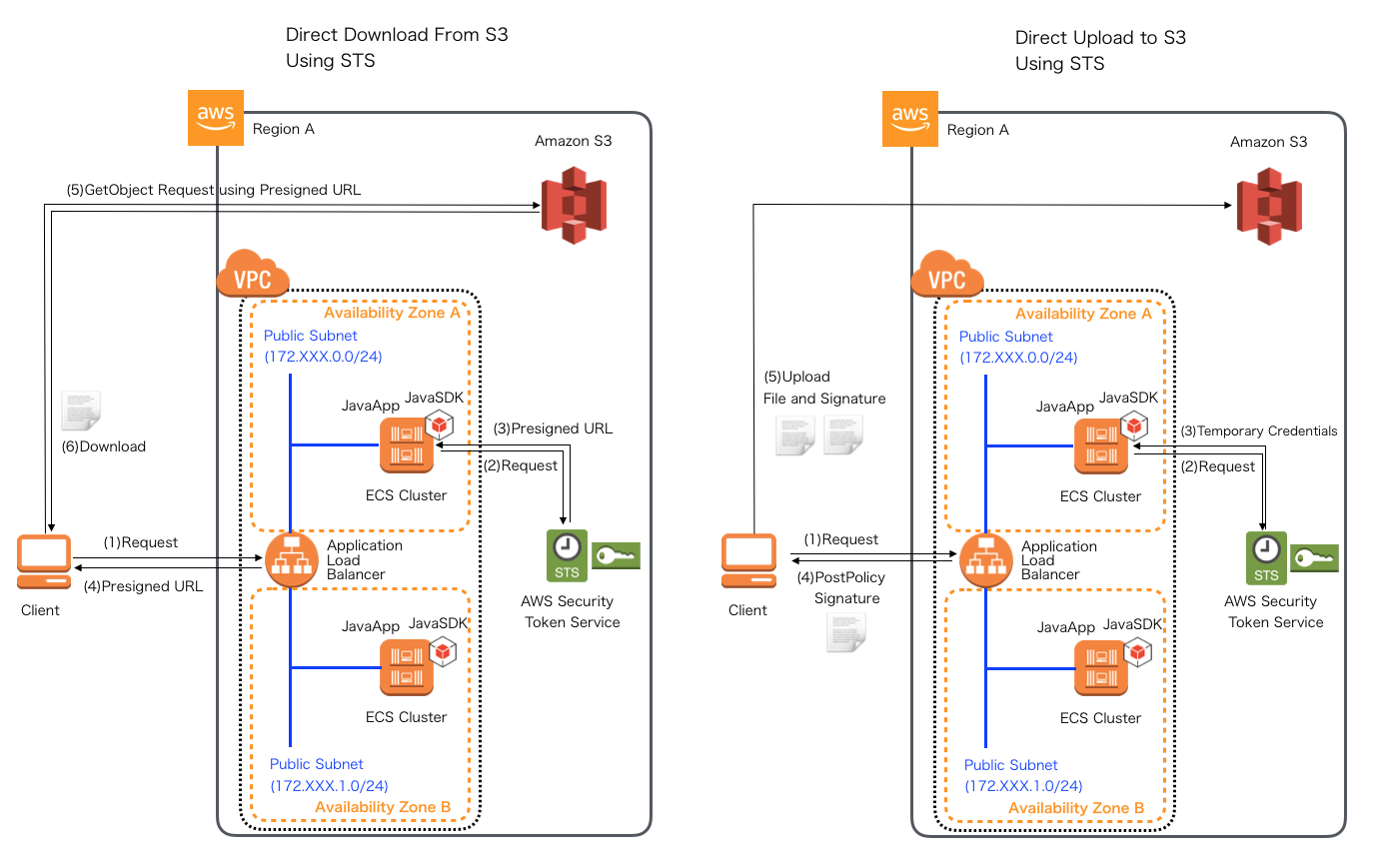
SQS編
[ポイント]SpringCloudAWSを使ったSQS Producer-Consumerアプリケーション
Producer設定クラス
@Configuration
public class SqsConfig {
@Value("${queue.endpoint}")
private String queueEndpoint;
@Value("${cloud.aws.region.static}")
private String region;
@Autowired
AmazonSQSAsync amazonSQSAsync;
@Bean
public AwsClientBuilder.EndpointConfiguration endpointConfiguration(){
return new AwsClientBuilder.EndpointConfiguration(queueEndpoint, region);
}
@Bean
public QueueMessagingTemplate queueMessagingTemplate(){
return new QueueMessagingTemplate(amazonSQSAsync);
}
}
[ポイント]SpringCloudAWSを使ったSQS Producer-Consumerアプリケーション
ProducerRepository
import org.springframework.cloud.aws.messaging.core.QueueMessagingTemplate;
@Component
public class SampleRepositoryImpl implements SampleRepository{
@Autowired
QueueMessagingTemplate queueMessagingTemplate;
@Override
public void save(Sample sample) {
queueMessagingTemplate.convertAndSend(
"MynaviSampleSqsQueue", sample.getMessage());
}
}
[ポイント]SpringCloudAWSを使ったSQS Producer-Consumerアプリケーション
Consumer設定クラス
@Configuration
public class SqsConfig {
@Value("${queue.endpoint}")
private String queueEndpoint;
@Value("${cloud.aws.region.static}")
private String region;
@Autowired
AmazonSQSAsync amazonSQSAsync;
@Bean
public AwsClientBuilder.EndpointConfiguration endpointConfiguration(){
return new AwsClientBuilder.EndpointConfiguration(queueEndpoint, region);
}
}
[ポイント]SpringCloudAWSを使ったSQS Producer-Consumerアプリケーション
Consumer※このバッチ実行だとスレッドセーフでない&多重起動はできないので注意
@EnableSqs
public class MessageListener {
@Autowired
JobLauncher jobLauncher;
@Autowired
Job job;
@SqsListener(value = "MynaviSampleSqsQueue", deletionPolicy = SqsMessageDeletionPolicy.ON_SUCCESS)
public void onMessage(String message) throws
JobExecutionAlreadyRunningException, JobRestartException,
JobInstanceAlreadyCompleteException, JobParametersInvalidException {
Map<String, JobParameter> jobParameterMap = new HashMap<>();
jobParameterMap.put("param", new JobParameter(message));
jobParameterMap.put("time", new JobParameter(System.currentTimeMillis()));
JobParameters jobParameters = new JobParameters(jobParameterMap);
JobExecution jobExecution = jobLauncher.run(job, jobParameters);
ExecutionContext executionContext = jobExecution.getExecutionContext();
}
}
[補足]SQS Queueを刈り取って実行するSpring Batchのサンプルの処理イメージ
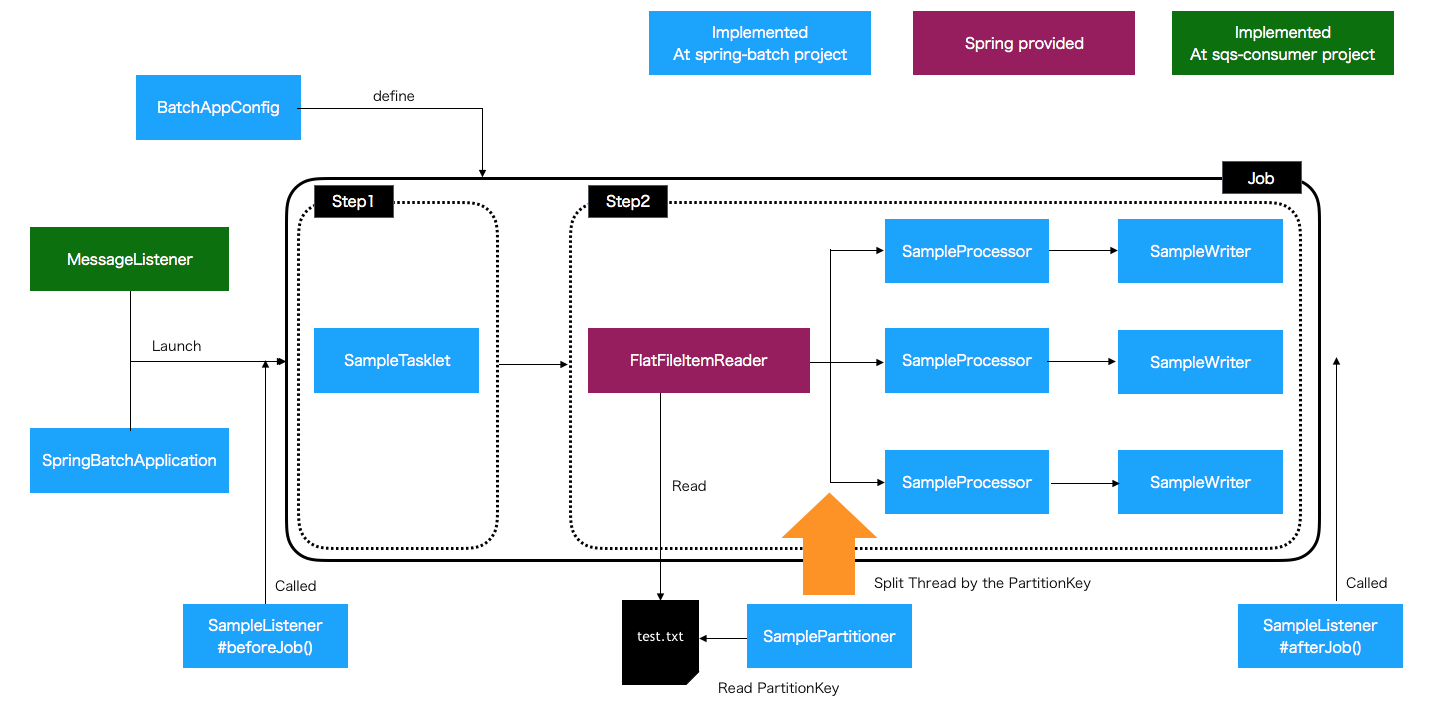
各テーマのポイント・補足
クラウドネイティブECSコンテナ編の環境でMSAアプリケーションを構築
クラウドネイティブECSコンテナ編の環境でMSAアプリケーションを構築
- DDDやオーケストレーション、コレオグラフィなどテーマが多岐に渡るので一旦省略。うまくサービス分割して、Controller、Service、Repositoryで実装が完了した想定
- ただ、幾つかのプロジェクトでチャレンジした結果、以下のような場合は上手くいかない(マイクロサービス化の目的を達成できない)。
- 過度の共通化(影響が大きくなって逆にアジリティを損なう)
- アプリケーション規模が大きすぎる(関係者も多くなるので。スモールスタートがよいのでは)
- マイクロサービス化の目的が明確でない(単に複雑になっただけ。モノリスの方が向いてたんじゃ…)
- 最初から完璧なモノを作ろうとする(リファクタリングを前提に考えた方がよい)
- 原理原則にこだわりすぎる(12FactorAppも全て満たすのすごく大変)
![]() 回避せよ!マイクロサービスの罠
回避せよ!マイクロサービスの罠

タイヤのブランコ=「素早くアプリを作って、早くサービスを提供したい」なのか?
出典:「オレゴン大学の実験」(C.アレグザンダ―・他著,B6判,203p,鹿島出版会,1977年12月): よく分かる解説
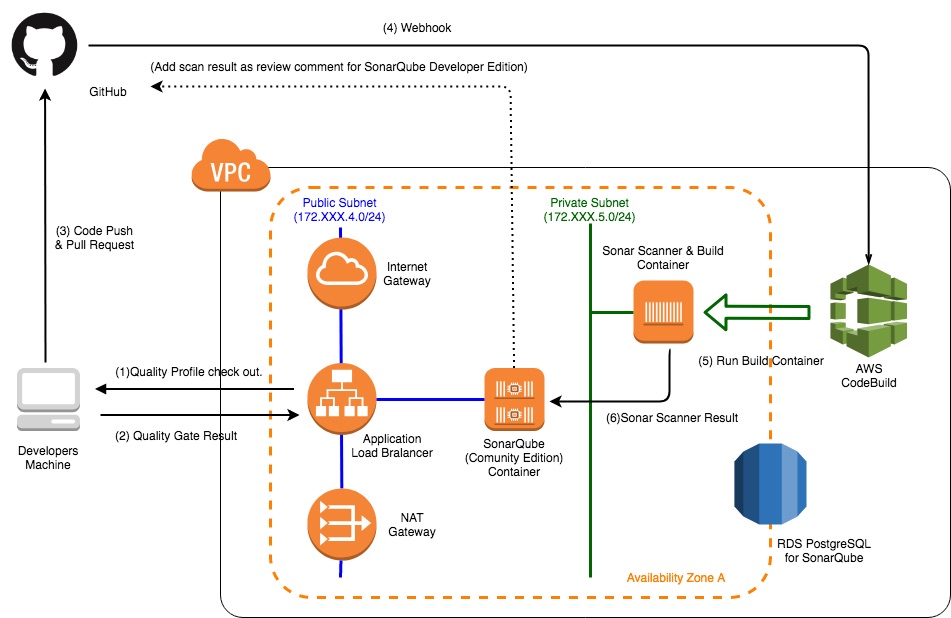
CI - 静的チェックツール環境導入編 -
[ポイント]SonarQubeServerをALB+ECS+RDSで構成のメリット
- SonarQubeServerをALB+ECSコンテナの運用で可用性を向上
- データベースをRDSにすることにより、バックアップ等保全性が向上
[補足]Spring.ioプロジェクトのSonarqubeプロジェクトはどうなっているか?
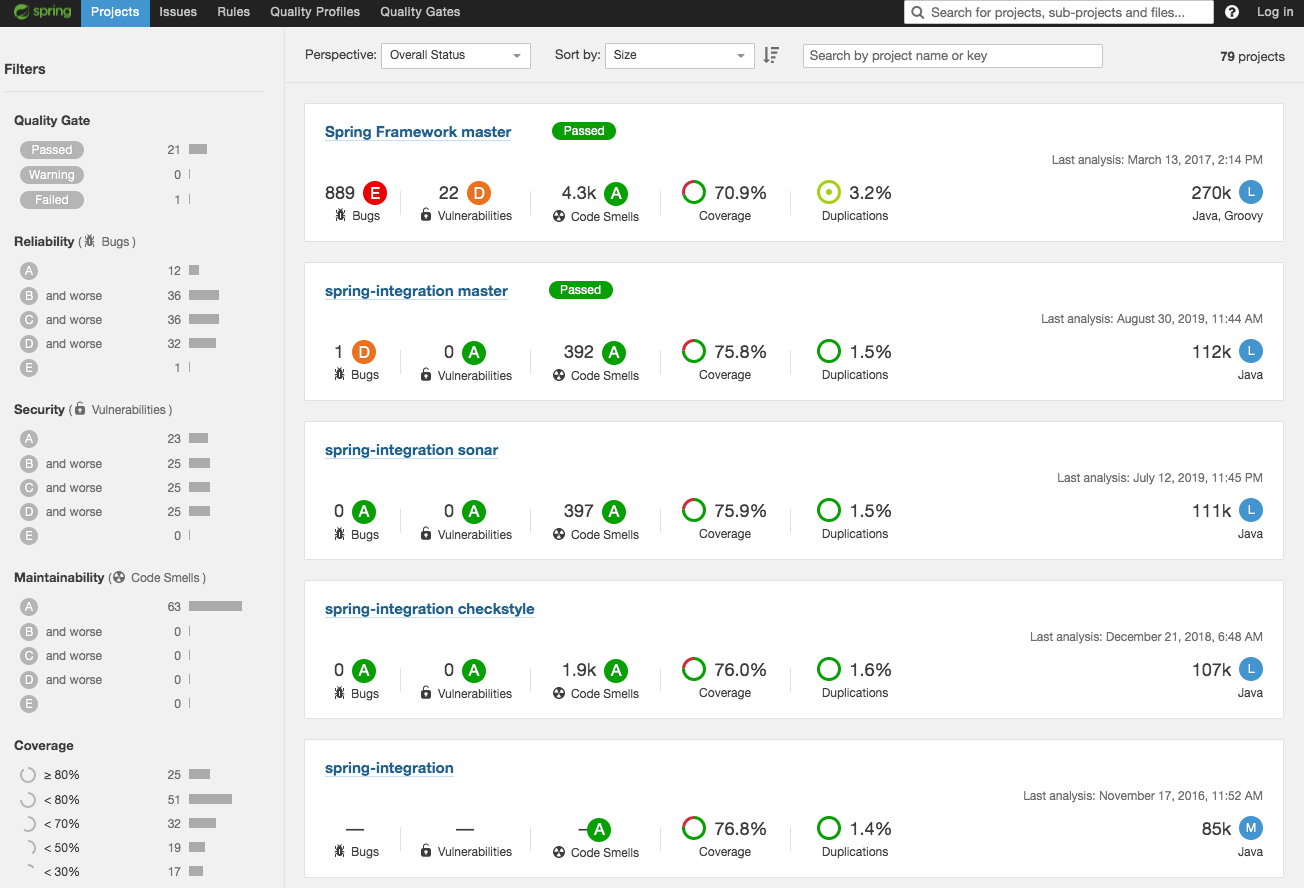
CI - SpringBootテストコード実装編 -
![]() 「テスト自動化の8原則」
「テスト自動化の8原則」
2. 手動でおこなって効果のないテストを自動化しても無駄である
3. 自動テストは書いたことしかテストしない
4. テスト自動化の効用はコスト削減だけではない
5. 自動テストシステムの開発は継続的におこなうものである
6. 自動化検討はプロジェクト初期から
7. 自動テストで新種のバグが見つかることは稀である
8. テスト結果分析という新たなタスクが生まれる
[補足]Configパッケージは必要?
一連の連載でSpringBootプロジェクトでメイン起動クラスや設定クラスは全てconfigパッケージにまとめています。Bootのオートコンフィグレーション機能を考えると、起動クラスはパッケージのルートヒエラルキー配下に配置しておいた方がよいかもしれませんが、 複数人の開発では、設定クラスの配置に関して何かしらのルールを設けないと設定クラスが拡散し、パッケージ変更するだけでAPやテストが起動できなくなる事象に度々遭遇します。そのため本連載では、@SpringBootTestなどの一部のアノテーションは、ルートヒエラルキーに起動クラスがないと実行されないなど多少不便&推奨から外れたとしても明示的に設定クラスを指定しないと逆に動かないような構成にしています。
CI - AWS CodeBuildによるCI実践編 -
[ポイント]クラウド型CIツールのメリット
- 複数並走開発していても、マシンリソースを気にせずテスト
- マスター・スレーブなど構成を気にせずシンプルにできる
AWS CodePipelineによるCD実践編
[ポイント]マイクロサービス間の連携テストはCDの中で自動化する
マルチOS・ブラウザでパラレル自動化テスト
[ポイント]ステージング環境とプロダクション環境のコンテナイメージは同一。AWS SysmtemsManagerで環境変数を切り替えるよう設定する。
今後の記事公開の予定
- SQSでいったん基本編は終了。発展編を執筆予定
- S3ダイレクトアップロード・ダウンロード
- Cognito+SpringSecurity認証認可
- EKS・AppMesh
- Cassandraの利用・AP型データベースデータモデル
- KinesisStream
- AWS IoT
- ElasticMapReduce
今後の記事公開の予定
- 執筆予定
- AWS CloudFormationを利用した基盤自動化
- AWS SystemsManager+CloudWatch