DataStore Category¶
Relational Database Service(RDS)¶
Overview¶
Relational Database Service(RDS)はセットアップや拡張、運用が容易なフルマネージドリレーショナルデータベースサービスである。 管理コンソールやAPIによって簡単にデータベースサービスを構築でき、時間単位の従量課金性である。EC2と同様、リザーブドインスタンスのオプションもあり、購入期間は定額で利用可能である。
RDSは以下の4つのデータベースエンジンを選択できる。
- MySQL
- PostgreSQL
- Oracle
- Microsoft SQL Server
RDSではデータベース運用管理では必須となる自動バックアップ機能及び冗長化構成による自動フェイルオーバをサポートしている。 自動バックアップ機能では、DBスナップショットとトランザクションログを保存している。DBスナップショットは1日1回、指定した世代数を、 指定した時間帯に取得する。リストアは任意の世代のDBスナップショットを指定して復元を行う。トランザクションログは随時取得されており、 任意に指定した状態へのリカバリが可能で、時刻は直近5分から、より古いスナップショットの時点の間で指定する。 データベース構築時には「Multi-AZ配置」と呼ばれる、レプリケーションによる冗長化構成(リードレプリカ)を選択できる。 この配置をとることで、マスターとなるRDSとは別のアベイラビリティゾーンに、スレーブとなるRDSを配置し、マスターからデータを複製する。 マスターに障害が発生すると、自動的にフェイルオーバし、スレーブがマスターに昇格する。Malti-AZ配置されたRDSは単一のエンドポイントを持つため、 マスターが変更された場合にも情報システム側で意識することなく、データベースを利用できる。 RDSへのアクセス制御はEC2と同様、Security Groupで設定する。データの暗号化機能もサポートされており、 暗号化キー管理サービス「Key Management Service(KMS)」に格納されたキーを使って暗号化できる。 MySQLとPostgreSQLではDBインスタンスの暗号化が、SQLServerとOracleでは、Transparent Data Encryption方式によるデータ暗号化がそれぞれ可能である。
Note
リードレプリカを作成した際には、マスター・スレーブ各々IPが割り振られるが、単一のCNAMEで、RDSエンドポイントが与えられるのでクライアントからはエンドポイントを参照すればよい。また、書き込み時はレプリカの書き込みも含め行われるのでリード側の一貫性は保証される。
Note
RDSのマスタースレーブはクロスリージョンでもサポートされる。
リザーブドDBインスタンスの購入¶
■マネージドコンソールにて、「Amazon RDS」サービスから、リザーブドDBインスタンスの購入ボタンを押下する。

■製品のエンジンや、インスタンスタイプ、スペック、可用性、個数、期間等を指定し、「次へ」ボタンを押下する。

■内容を確認し、購入ボタンを押下する。

Aurora¶
クラウド時代にAWSが再設計したRDBMS
- スケールアウト、分散、マルチテナント
- AWSサービスを活用したサービス志向アーキテクチャ
- フルマネージド
ストレージの書き込み方式にクォーラムモデルを採用しているため、高可用性を実現している。
[Auroraが向くユースケース]
- OLTP向けのスループット最適化(数千TPSといった負荷がかかっても性能が落ちないように最適化)
- 堅牢性(3つのAZに跨りデータをコピーする必要がある)を求めるデータ
[メモ]
Aurora StorageのIO(Read/Write形式の特徴)
- SSDをシームレスにスケール(10GB->64TB)
- 高可用性 データを3AZに6つのストレージ(ノードとしては、10GBの数百のストレージノードにストライピングされている) 同期(レプリケーション)するとレイテンシが遅延、非同期するとデータがロストする可能性するので Quorum(クォーラムモデル)4/6方式により解決
- MTTR(平均復旧時間)を短縮
キャッシュレイヤの分離 DBプロセスが再起動してもキャッシュが残る
[Aurora MySQL]
- 高速化したフェイルオーバー
- Custom Endpoint Auroraクラスタ内のどのインスタンスを含めるか、ユーザが指定可能なエンドポイントが作成可能 オンラインクエリ用のリードレプリカ、分析用のリードレプリカをエンドポイントで分離可能になった。
- Aurora Serverless - HTTPSエンドポイントも提供 - あまり使用されないアプリケーションなどがユースケース
- Global Database Auroraでサポートしていたクロスリージョンレプリケーションで使用していたBinlogを使わず、直接別のリージョンで物理コピーを行うので、 低レイテンシーで別リージョンのデータリードが可能。
[PostgreSQL]
- PostgreSQL9.6及び10互換
- RDS for PostgreSQLで利用可能な拡張モジュールを利用可能
* Redshift -> PostgreSQLへのdblink機能
[新機能]
- PostgreSQL10.4、10.5互換
- ネイティブ・パーティショニング(宣言的パーティショニング)
- パラレルクエリ強化(パラレルクエリのScan、Join方式の追加)
- postgres_fdw強化(リモートサーバの集約に対応)
- Aurora Serverless
- QPM(Query Plan Management) 実行計画の変更やそのタイミングを制御可能
ElastiCache¶
ElastiCacheはデータベースの応答をキャッシュに保存し高速化する。ElastiCacheでは「memcached」と「Redis」という2種類の インメモリキャッシュエンジンをサポートしている。
- memcached
- マルチスレッド
- No Persitence
- Flat string ElastiCache
- low maintainance
- easy to scale holizontally
単純なキーバリューモデルで、複数ノード間のキャッシュレプリケーションなどの冗長化機能がないため、 可用性はアプリケーション側で確保する必要がある。
- Redis
- Single thread
- Persistence
- Hash型
- Rate Limiting
キャッシュデータ(読み取り専用、冪等、繰り返しアクセス、生存期間が長い)とは
- ブラウザキャッシュ JS、CSS
- Webサーバキャッシュ
- キャッシュストレージ -> ElasticCacheのカバー範囲 APIの結果
- データストアキャッシュ -> ElasticCacheのカバー範囲 クエリキャッシュ
- キャッシュパターン * Be Lazy * White On Through * StoringJson
以下のような観点で使い分けを行う。
| Memcached | Redis | |
| アクセス | マルチスレッド | シングルスレッド |
| データ構造・タイプ | シンプル | 文字列からリスト・ハッシュ等複雑なデータ型をサポート |
| 永続性 | なし | あり |
| マルチAZとフェイルオーバー | なし | あり |
| その他の特徴 | 水平スケール可能 | スケールアウトは更新がマスターノードに集中するため不可(リードレプリカは可) |
DynamoDB¶
Overview¶
DynamoDBはAmazonが設計・開発していたNoSQLデータベース「Amazon Dynamo」をベースにサービス化したデータストアである。 NoSQLではトランザクションによるデータ一貫性を保証する代わりに、結果整合性を担保することでクラスタ内の全ノードでの読み書きを可能にしている。 つまり、データ更新直後は古いデータを取得する可能性があるが、結果的に全て最新の状態で更新される。 DynamoDBもその他のAWSサービスと同様、従量課金制で、基準は指定したリクエストスループットと保存されたデータ量により決定される。 DynamoDBの設定では、テーブルごとに目標とする書き込みと読み込みのリクエストスループットを、キャパシティーユニットとして、以下のいずれか指定する。
- 読み込みキャパシティーユニット
- 最大4KBのデータを上限に、強い整合性のある読み込みを1秒あたり1回
- 最大4KBのデータを上限に、結果整合性のある読み込みを1秒あたり2回
- 書き込みキャパシティーユニット
- 最大1KBのデータを上限に、書き込みを1秒あたり1回
DynamoDBは指定されたリクエストスループットに基づいて、自動的に必要なコンピュータリソースを確保する。 保存されたデータ量によって課金されるが、データ容量は自動的に増加される。
Warning
DynamoDBのデータは1項目(1行)あたり400KBのため、バイナリデータなどサイズの大きくなりがちなデータは保存できないので注意。
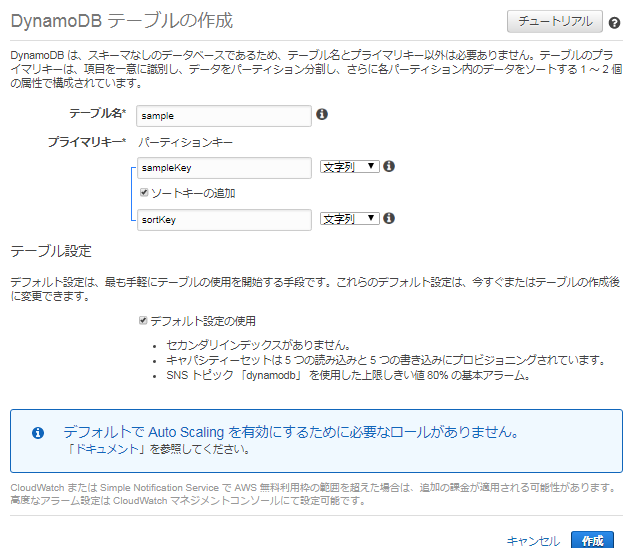
- パーティションキー、ソートキー
- ローカルセカンダリインデックス:SortKey以外で絞り込み検索を行うキーを持つ。すべての要素(テーブルとインデックス)の合計が10Gb
- グローバルセカンダリインデックス:PationKeyの属性の代わりとなるキー。他のカラムとPationKeyを組み合わせ検索条件とする。20個まで
- DynamoDB Transaction
- DynamoDB Key Diagnostics Library
- DynamoDB Accelator(DAX):フルマネージドで高可用性の、DynamoDB 用インメモリキャッシュ
- データモデル
- グローバルセカンダリインデックス(GSIの制限はデフォルト最大20まで)
- Composite Key(Attributeの結合)
- Sparse index
- GSI OVERLOADING(GSIとして利用する属性を複数にまとめてしまい、GSIの数を減らす方法)
- GSIのキーとなるデータが大きすぎる場合、キーとなる項目のポインタとなるIDなどを作成してテーブル分割する。
- DynamoDB Trigger:DynamoDBの書き込みに応じて別処理をLambdaでトリガーする。
- DynamoDB TTL:テーブルの項目を期限切れにする特定のタイムスタンプを設定する機能
- ホットデータとコールドデータでテーブルを分けること
- 特定のパーティションキーに読み込みが集中する場合は、DAXを活用すること。
- 書き込みが特定のテーブルに集中する場合は、キュー(SQS)やストリーム(kinesis)を間に挟んで緩和する。もしくはプライマリキーにUUIDや乱数などで書き込むノードを分散させる。
- グローバルセカンダリインデックス(GSIの制限はデフォルト最大20まで)
- データモデルの設計方法:まずデータアクセスのユースケースをすべて洗い出すこと。
- データモデルが似ているCassandraではNETFIXから Astyanax が提供されている。
- グローバルテーブルでも各リージョンごとにDynamoDBのテブールが構築され、データが(非同期で)リプリケーションされていく(コリジョンした場合は後勝ち)。マルチリージョンごとにノードが作られるわけではない。
Spring Data DynamoDBの利用¶
Introduction を参照のこと。
Redshift¶
Redshiftは大量データを使った集計や分析に特化したデータウェアハウス・サービスである。同様に従量課金性であるが、主な特徴は、
- 高速性
- 拡張性
- 互換性
RedshiftはSQLクエリを高速化するために、列指向データベースを採用している。一般的なリレーショナルデータベースが行指向型でレコードを取得するクエリに向いているのに対し、列指向データベースでは、カラム単位でのデータを高速に集計できる。他のAWSサービスと同様、スケーラブルな特性を持ち、パフォーマンスやデータ保存ストレージが不足してもすぐにノード数や性能タイプを変更でき、MPP(Massively Parallel Processing:大規模並列計算)機構を持ち、全ノードが並列に処理するため、ノード数を増やせば処理性能も向上する。また、Redshift用にカスタマイズされたJDBCやODBCのドライバーが用意され、既存のSQLをそのまま流用でき、PostgreSQL用のドライバーを流用することが可能である。なお、既存のETL(Extract/Transform/Load)ツールやTableauといったBIツールを利用することもできる。
Note
RedShiftの実態はPostgreSQLのため、流用することが可能である。