【第16回】NoSQL(3)-DynamoDB-Amazon DynamoDBの概要及び構築と認証情報の設定¶
クラウドの普及に伴い、ビッグデータやキーバリュー型データの格納など、ますます活用の機会が広がりつつあるNoSQLデータベース。 第3回は代表的なNoSQLプロダクトであるAmazon DynamoDBやApache Cassandra、Amazon ElastiCacheへアクセスするSpringアプリケーションを開発する方法について、わかりやすく解説します。
本連載では、以下の様なステップで進めています。
- NoSQLデータベースの特徴とデータ特性
- CAP定理を元にしたデータベースの分類とデータ特性
- AP型データベースAmazon DynamoDBとApache Cassandraの特徴
- Amazon DynamoDBへアクセスするSpringアプリケーション
- Amazon DynamoDBの概要及び構築と認証情報の作成
- Spring Data DynamoDBを用いたアプリケーション(1)
- Spring Data DynamoDBを用いたアプリケーション(2)
- Apache CassandraへアクセスするSpringアプリケーション
- Apache Cassandraの概要及びローカル環境構築
- Spring Data Cassandraを用いたアプリケーション(1)
- Spring Data Cassandraを用いたアプリケーション(2)
- Amazon ElastiCacheへアクセスするSpringアプリケーション
- AmazonElasiCacheの概要及びローカル環境でのRedisServer構築
- Spring SessionとSpring Data Redisを用いたアプリケーション(1)
- Spring SessionとSpring Data Redisを用いたアプリケーション(2)
- Amazon ElastiCacheの設定
- セッション共有するECSアプリケーションの構築(1)
- セッション共有するECSアプリケーションの構築(2)
前回 AP型データベースAmazon DynamoDBとApache Cassandraの特徴 では、AP型データベースである、Amazon DynamoDB及びApache Cassandraについて、分散モデルやデータ配置、リレーショナルデータベースとの機能的な差異を整理しました。 今回はAmazon DynamoDBの概要を説明し、実際に構築してみます。
Amazon DynamoDBの概要¶
Amazon DynamoDBは、AWSフルマネージドなAP型NoSQLデータベースで、特に項目属性定義が必要ないスキーマレスのテーブル構成です。 リージョンごとにデータベースが構築されるサービスであり、異なるアベイラビリティゾーンにデータが3箇所レプリケーションされます。 データは以下の通りのオプションで、読み込みは結果整合性か強い読み込み整合性かを選択できます。
| 結果整合性のオプション | ||
| 読込 | 【結果整合性のある読込】 | 2/3以上の読込で結果一致した場合正常応答 |
| 【強い読込整合性】 | 全てのReadRepairが完了している状態で、結果を応答 | |
| 書込 | 【結果整合性のある書込】 | 2/3以上の書込が成功した場合正常応答 |
データを一意に識別するためのプライマリーキー(PrimaryKey)は、パーティションキー(PartitionKey)あるいはソートキー(SortKey)との組み合わせで構成されます。 原則プライマリーキー以外の検索はできませんが、代わりに任意の属性をパーティションキーとするグローバルセカンダリインデックス(GlobalSecondaryIndex:GSI)と パーティションキーと別の属性とを組み合わせて作成するローカルセカンダリインデックス(LocalSecondaryIndex:LSI)が利用できます。
また、DynamoDBでは、AWSの各種サービスと統合されています。デフォルトでIAMによりきめ細やかにアクセス制御され、実行メトリクスをCloudWatchと連携されますし、 AWS Lambdaと統合して、項目レベルの変更が発生した場合に、通知を送信できます。また、Amazon Elasticsearchを使ってDB項目のフリーテキスト検索が可能になります。
加えて、DynamoDBはクロスリージョンでグローバルテーブルの構築が可能です。複数のリージョンで同一のデータを参照・更新できますが、 複数のリージョンを跨いで1つのテーブルとなる様にデータノードを配置するのではなく、リージョンごとにレプリケーションを作成する形になります。 そのため、異なるリージョンでほぼ同時に更新が発生した場合、レプリカテーブルへの反映は数秒程度で反映されますが、最新の書き込みの方が反映されるため注意が必要です。
注釈
ローカルセカンダリインデックスはテーブルとインデックスの合計サイズが各パーティションキーごとに20GBまでで制限されます。
Amazon DynamoDBの構築¶
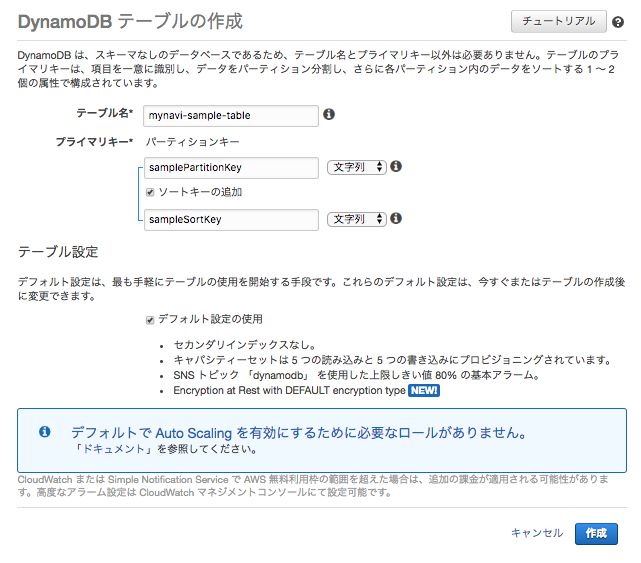
それでは、DynamoDBを構築してみましょう。AWSコンソールの「DynamoDB」サービスから、「テーブルの作成」ボタンを押下し、以下の要領に則って入力します。
- テーブル名:任意のテーブル名を入力
- プライマリーキー:パーティションキー及びオプションでソートキー名を入力。
- デフォルトの設定:チェックする
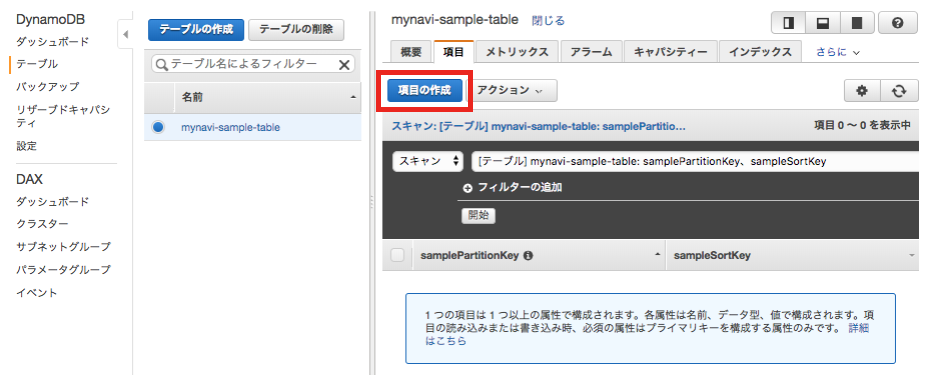
データベースの作成は以上で完了です。合わせてコンソール上からテーブルにデータを追加してみましょう。作成したテーブルを選択し、「項目」タブから「項目の作成」ボタンを押下してください。
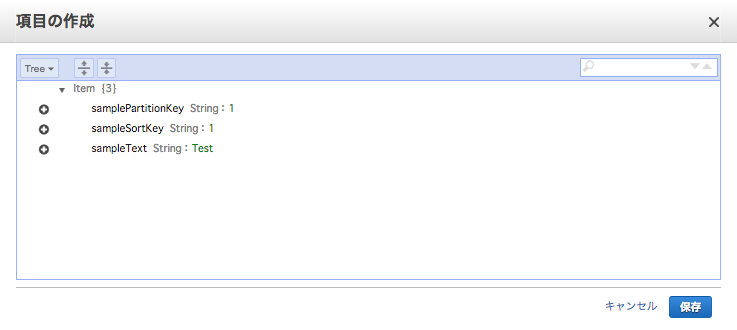
パーティションキーやソートキーに加えて、テキストデータを「sampleText」という属性名を追加してデータ追加し、「保存」ボタンを押下します。
ユーザ・認証情報の作成¶
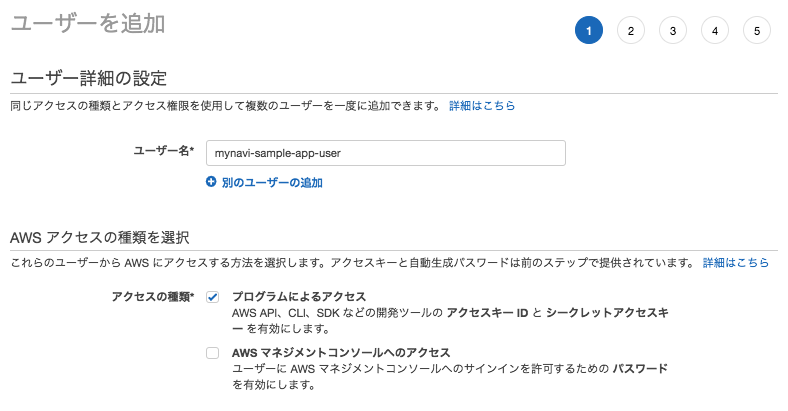
次回以降作成するアプリケーションでローカル環境からDynamoDBへアクセスするために必要なユーザ及び認証情報を作成しておきましょう。 「IAM」サービスから「ユーザ」メニューを作成し、「ユーザの作成」ボタンを押下し、以下の要領に則って入力してください。
- ユーザ名:任意の名前を入力
- アクセスの種類:アプリケーションからアクセスするユーザを作成するので、「プログラムによるアクセス」を選択します。
アクセス権限を追加します。グループを作成しても良いですが、ここでは、直接ユーザにDynamoDBのフルアクセス権限ポリシーをアタッチしましょう。 「既存のポリシーを直接アタッチ」を選択し、「AmazonDynamoDBFullAccess」を選択してください。
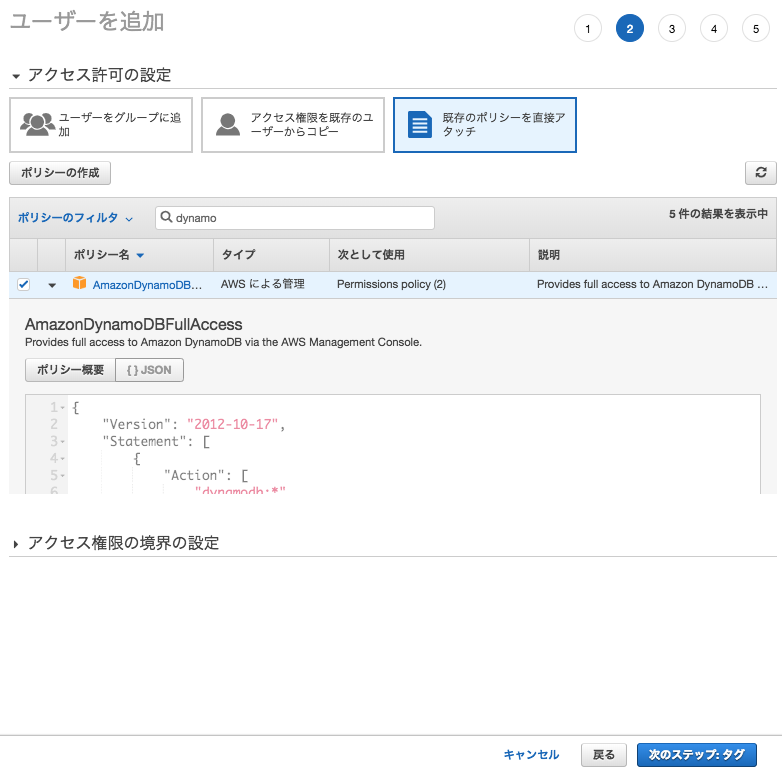
タグは特に設定しなくてもかまいません。
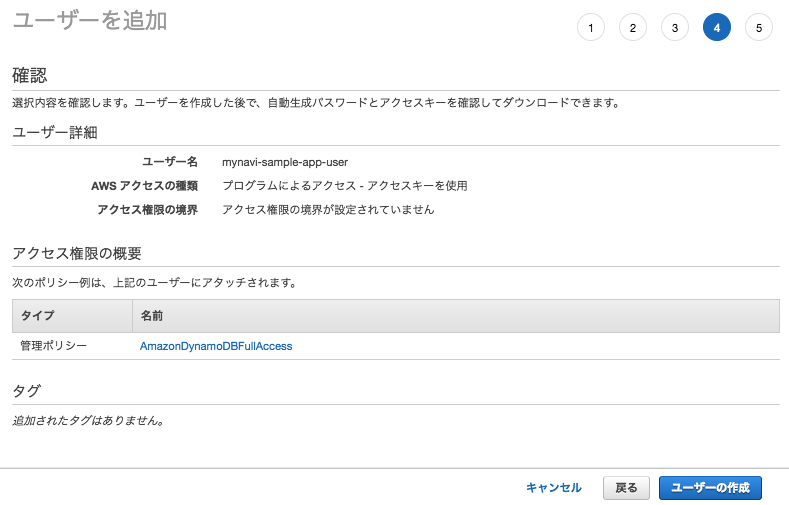
設定内容が正しいかを確認したら、「ユーザの作成」ボタンを押してください。
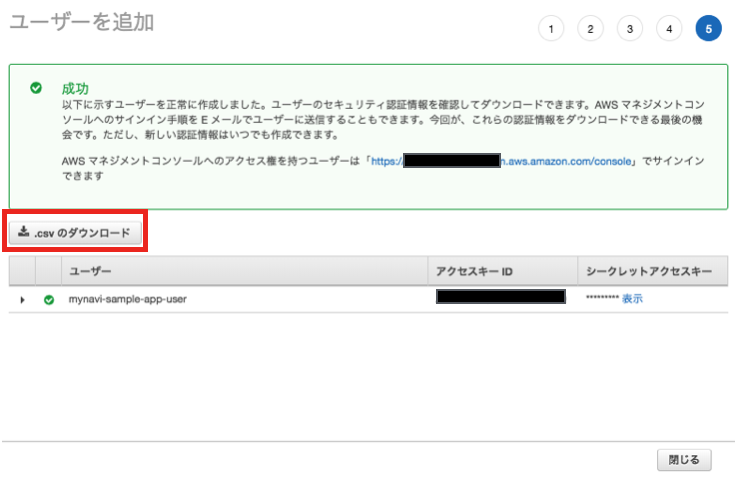
ユーザが作成されます、アクセスキーIDとシークレットアクセスキーが表示されますが、ここで、CSV形式でこの認証キーをダウンロードしておいてください。
以上で、DynamoDBの作成は完了です。次回はこのテーブルにアクセスするSpringアプリケーションを作成します。
著者紹介¶
川畑 光平(KAWABATA Kohei)

某システムインテグレータにて、金融機関システム業務アプリケーション開発・システム基盤担当を経て、現在はソフトウェア開発自動化関連の研究開発・推進に従事。
Red Hat Certified Engineer、Pivotal Certified Spring Professional、AWS Certified Solutions Architect Professional等の資格を持ち、アプリケーション基盤・クラウドなど様々な開発プロジェクト支援にも携わる。
2019 APN AWS Top Engineers & Ambassadors 選出。
本連載記事の内容に対するご意見・ご質問は Facebook まで。