【第25回】AmazonS3へSpringCloudAWSを使ってアクセスするアプリケーション実装(1)¶
クラウド上のストレージとして、AWSで利用可能なAmazon S3。今回はSpring Cloud AWSを用いてAmazon S3へアクセスするSpringアプリケーションの実装方法について解説します。
本連載では、以下のステップで解説を進めていきます。
- Amazon S3の概要とバケットの作成・ファイルのアップロード
- Spring Cloud AWSを用いたアプリケーション実装(1)
- Spring Cloud AWSを用いたアプリケーション実装(2)
なお、本連載は以下の前提知識がある開発者を想定しています。
| 対象読者 | 前提知識 |
| エンタープライズ開発者 | Java言語及びSpringFrameworkを使った開発に従事したことがある経験者。経験がなければ、 こちらのチュートリアル を実施することを推奨します。TERASOLUNAはSpringのベストプラクティスをまとめた開発方法論で、このチュートリアルでは、JavaやSpring Frameworkを使った開発に必要な最低限の知識を得ることができます。 |
| GitHubなどのバージョン管理ツールやApache Mavenなどのライブラリ管理ツールを使った開発に従事したことがある経験者。 | |
| AWS開発経験者 | AWSアカウントをもち、コンソール上で各サービスを実行したことがある経験者 |
また、動作環境は以下のバージョンで実施しています。
| 動作対象 | バージョン |
| Java | 1.8 |
| Spring Boot | 2.1.6.RELEASE |
| Spring Cloud AWS | 2.1.2.RELEASE |
将来的には、AWSコンソール上の画面イメージや操作、バージョンアップによりJavaのソースコード内で使用するクラスが異なる可能性があります。
Amazon S3の概要¶
Amazon S3(Simple Storage Service)は、各リージョン毎で利用可能なWebベースのデータストレージサービスで、基本的にAWSコンソールやアプリケーションを経由して、データの保存や取出しが可能です。保存できるファイル数に限界はありませんが、 1ファイルあたり最大5TBに制限されます。
保存先のストレージの主な特徴として、データセンタ内の複数ストレージに必ず3箇所以上に複製されることにより、 きわめて高い信頼性を確保する(イレブン9のオーダー)とともにファイルにバージョンが付与可能なため、ユーザの誤操作による復元も可能となっています。 なお、S3のデータは同一リージョンの専用のデータ領域に保存されます。
データは、ユーザが最初に作成する「バケット」と呼ばれる保存場所に「オブジェクト」として、アップロードする形となります。 オブジェクトを保存するときは、オプションでスタンダード、低冗長化、標準IA、Glacierが選択できます。 発生料金は、概ね以下の通り、データ使用量に応じた従量課金性(リージョンにより単価は異なる)ですが、信頼性とアクセス頻度に応じて異なります。
| オプション | 信頼性 | 料金 |
|---|---|---|
| スタンダード | 99.999999999% | 1GBあたり3円程度 |
| 低冗長化 | 99.99% | スタンダードの2/3 |
| 標準IA | 99.999999999% | スタンダードの2/3 ただし、アクセス料金が高い |
| Glacier | 99.999999999% | スタンダードの1/3 データの取り出しに数時間必要。 |
S3へアクセスする全ての通信はSSLによって暗号化され、バケットごとにポリシーを設定でき、アクセスを詳細に制御可能です。 アップロードデータの自動暗号化機能もあり、こちらを有効化すると情報漏洩が発生してもデータの参照はできません。
また、S3はWebサーバとしても動作し、アップロードされたデータをそのままコンテンツとして保存できます。 ただし、スクリプト言語やデータベースの導入はできないため、動的なコンテンツは利用できませんが、HTMLや画像ファイルなどの静的なコンテンツならば、 信頼性が高いWebサイトをそのまま構築することが可能です。
バケットの作成とファイルのアップロード¶
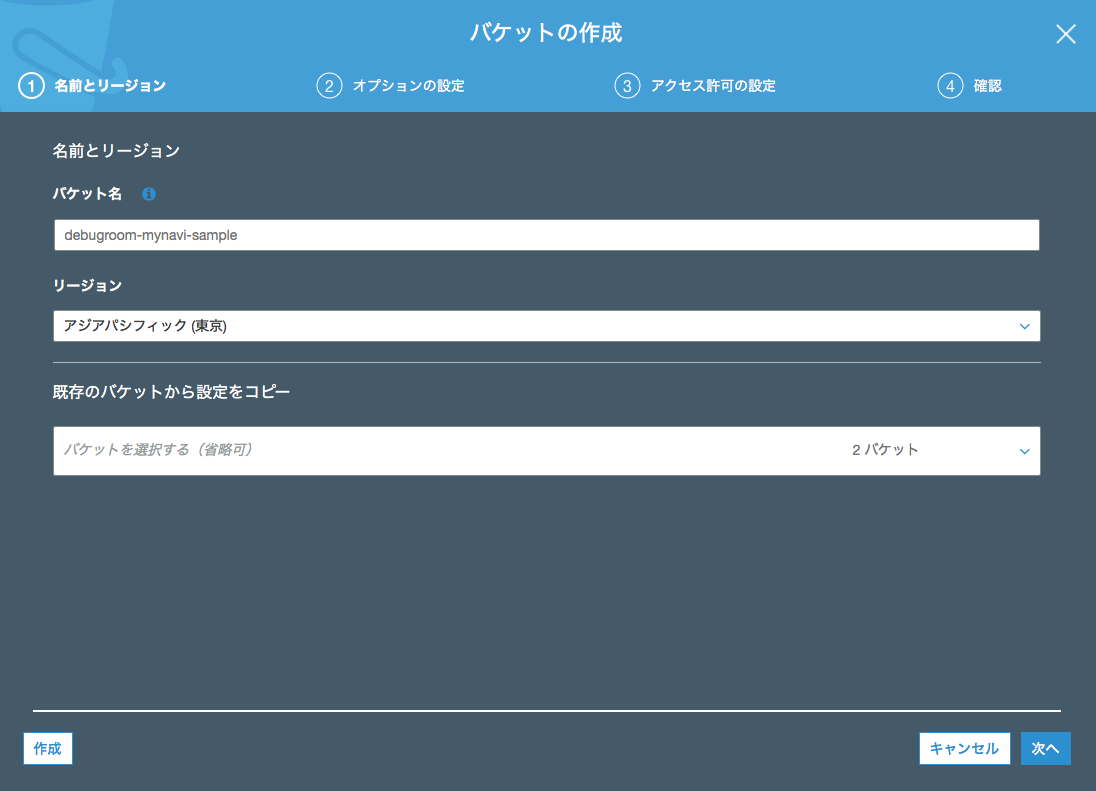
まず最初にデータを保存するためのバケットを作成しましょう。AWSマネジメントコンソールからS3サービスメニューを選択し、「バケットを作成する」ボタンを押下して、バケット名とリージョンを選択します。
警告
バケット名には小文字の英文字、数字およびハイフン(-)やドット(.)を含むことができますが、S3へのダイレクトアップロード時などにドットを含めるとエラーとなるため、AWS 公式ページ「バケット命名規則」 に従って、バケット名を作成してください。なお、作成後にバケット名を変更することはできません。
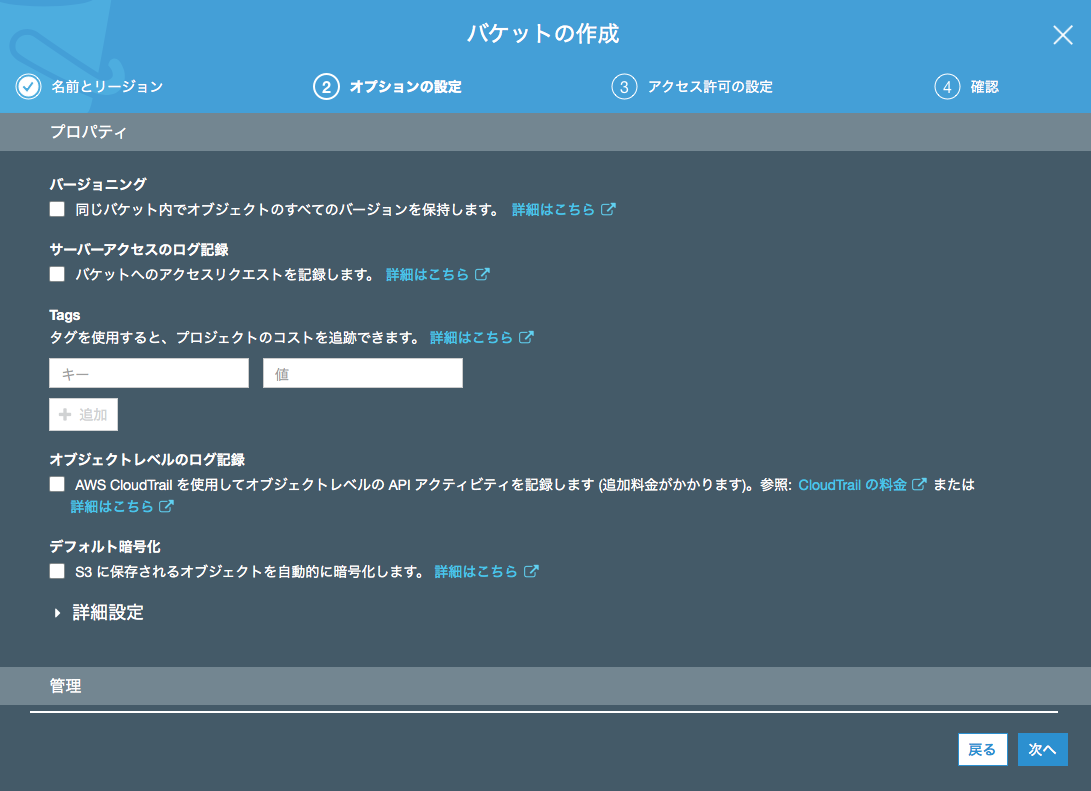
オプションは今回は何も設定せず、「次へ」ボタンを押下します。
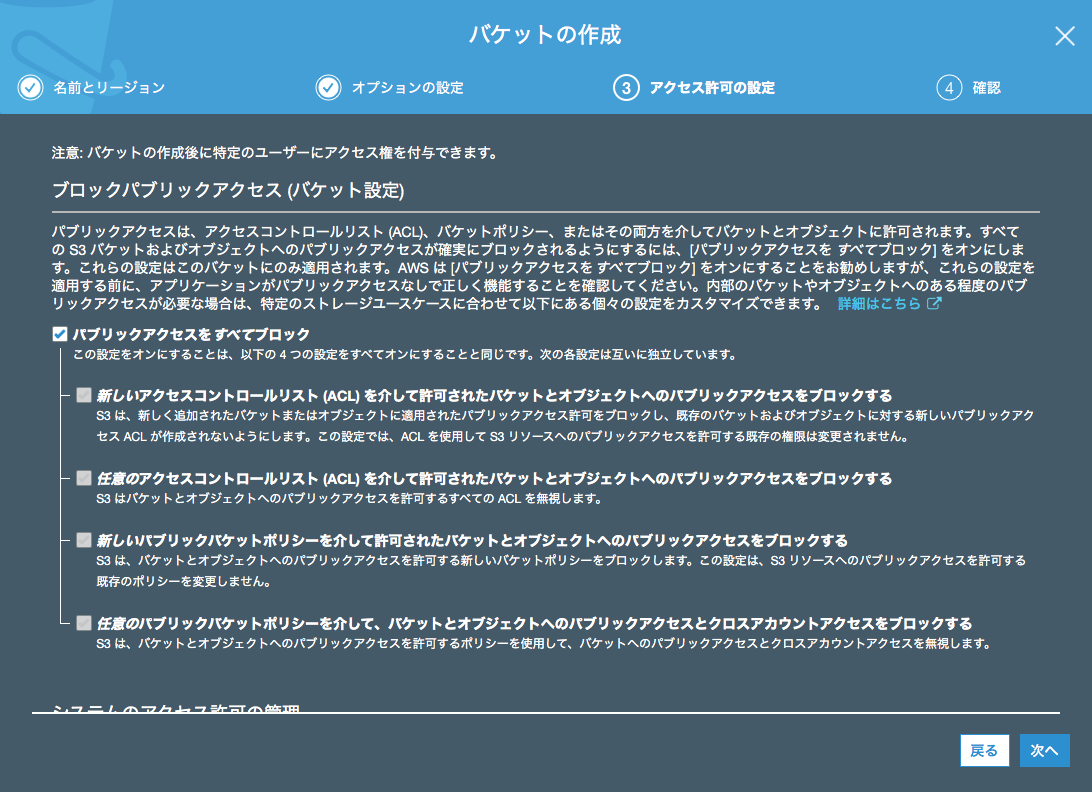
アクセス制御ではパブリックアクセスをブロックしておきます。
警告
最近では、S3のドメインを自動スキャンしてパブリックアクセスが可能なバケットに悪意のあるJavaScriptのコードを埋め込むセキュリティ攻撃が確認されているため、開発や検証用途のバケットだとしても基本的にパブリックアクセスは避けるように設定しましょう。
設定内容を確認し、「バケットを作成」ボタンを押下します。
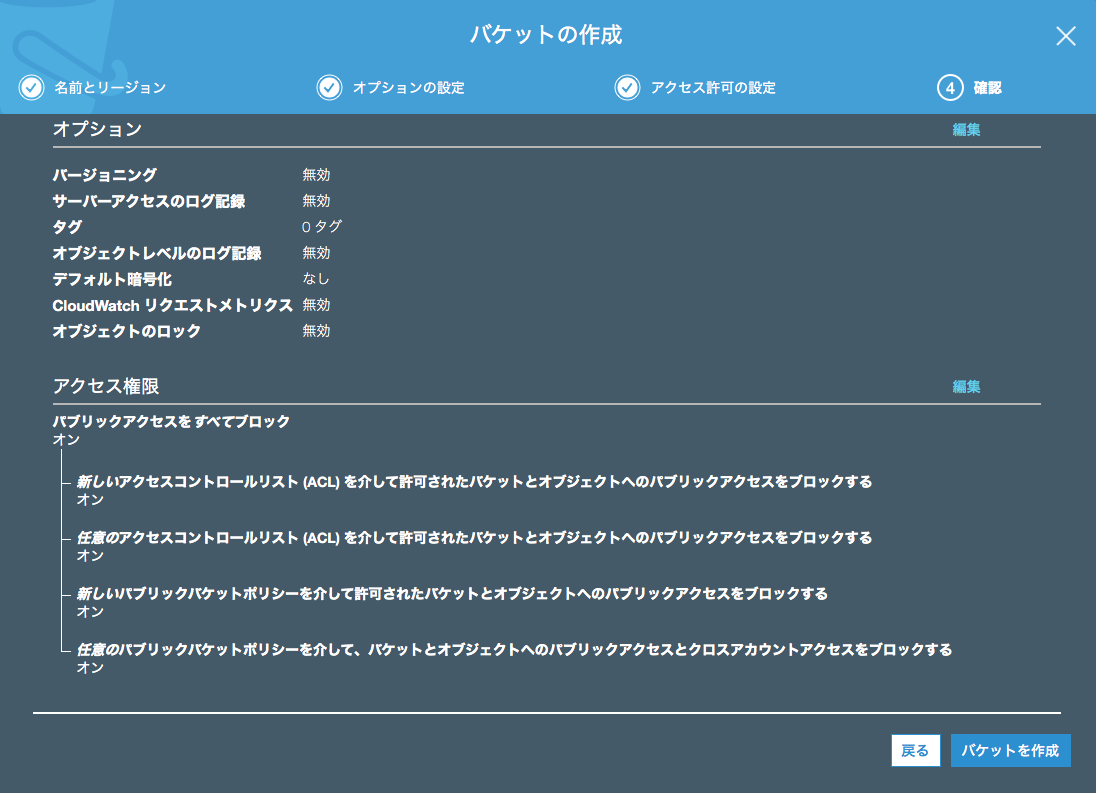
バケットを作成できたら、ファイルをアップロードしてみましょう。作成したバケットを選択し、「アップロード」ボタンを押下します。 ダイアログが出てきたら「ファイルを追加」ボタンを押下し、ファイルを選択します。選択したら「次へ」ボタンを押下します。
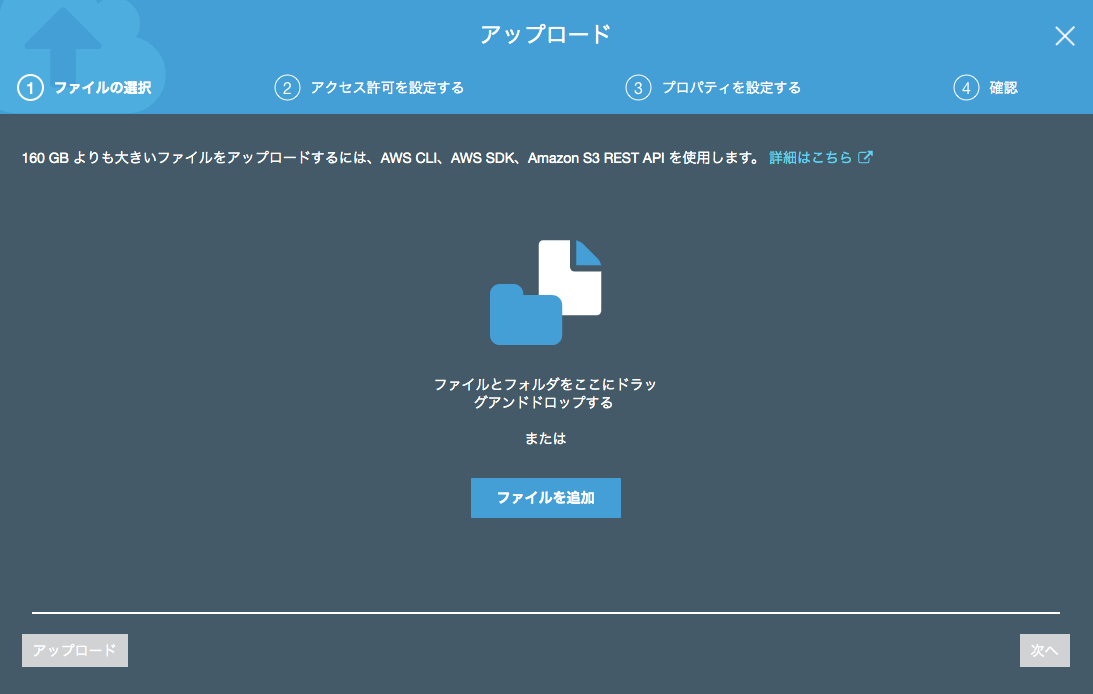
注釈
Amazon S3 では、オブジェクトのキー名に基づきバケットが仕切られるため、タイムスタンプやアルファベット順など、重複するプレフィックスを使用すると、特定のパーティションが使用される確率が高くなります。S3のリクエストのワークロードが1秒につき、100を超えるPUT、LIST、DELETE、あるいは300を超えるGETが見込まれるとき、ガイドライン に従い、パフォーマンスの向上のためにバケット名の先頭に異なる英数字の使用を検討しましょう。
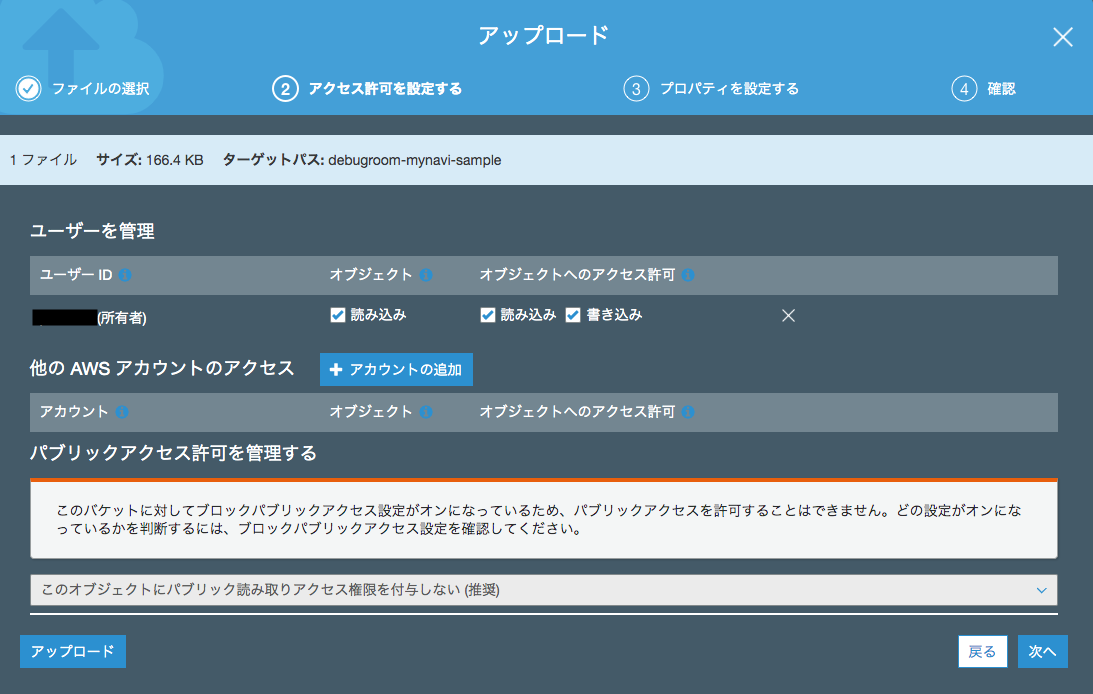
アップロードするファイルへのアクセス権限を設定します。ここではデフォルトのまま所有者のみアクセス権限を設定しておきます。
アップロードするファイルのストレージオプションを選択します。ここでは「スタンダード」を選択します。
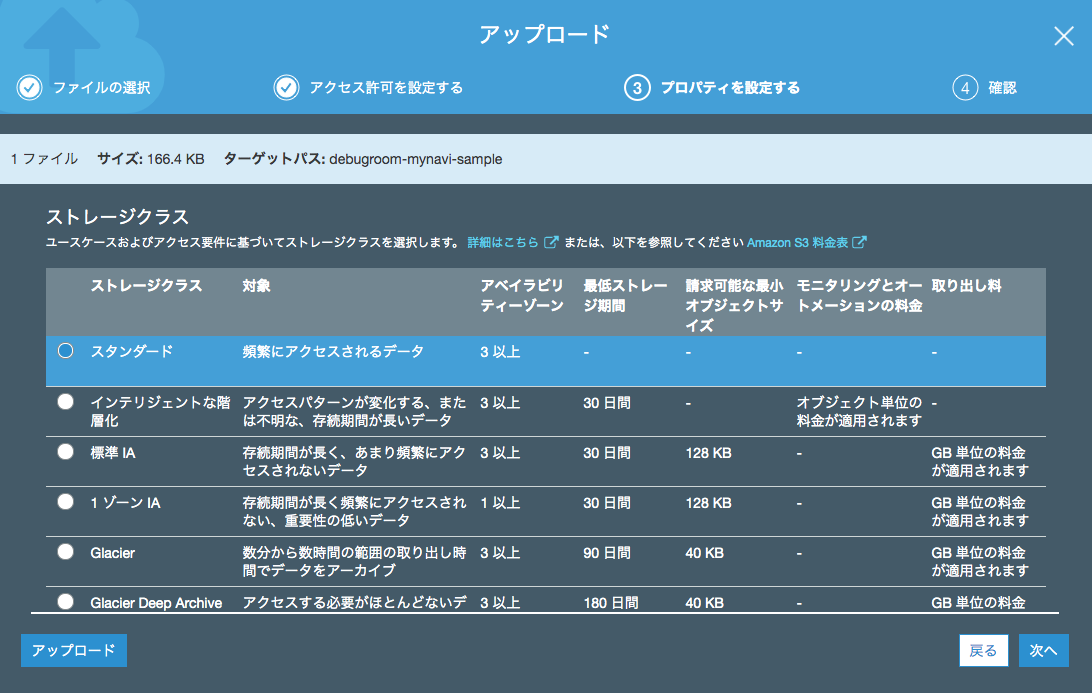
内容を確認したら「アップロード」ボタンを押下します。

これでファイルのアップロードができました。次回は、SpringアプリケーションでS3へアクセスする方法を説明し、実装していきます。
著者紹介¶
川畑 光平(KAWABATA Kohei)

某システムインテグレータにて、金融機関システム業務アプリケーション開発・システム基盤担当を経て、現在はソフトウェア開発自動化関連の研究開発・推進に従事。
Red Hat Certified Engineer、Pivotal Certified Spring Professional、AWS Certified Solutions Architect Professional等の資格を持ち、アプリケーション基盤・クラウドなど様々な開発プロジェクト支援にも携わる。
2019 APN AWS Top Engineers & Ambassadors 選出。
本連載記事の内容に対するご意見・ご質問は Facebook まで。