【第11回】AWS X-Rayを用いたマイクロサービスの可視化(4)¶
本連載では、以下に示すようなマイクロサービスアーキテクチャのアプリケーション環境を構築しています。
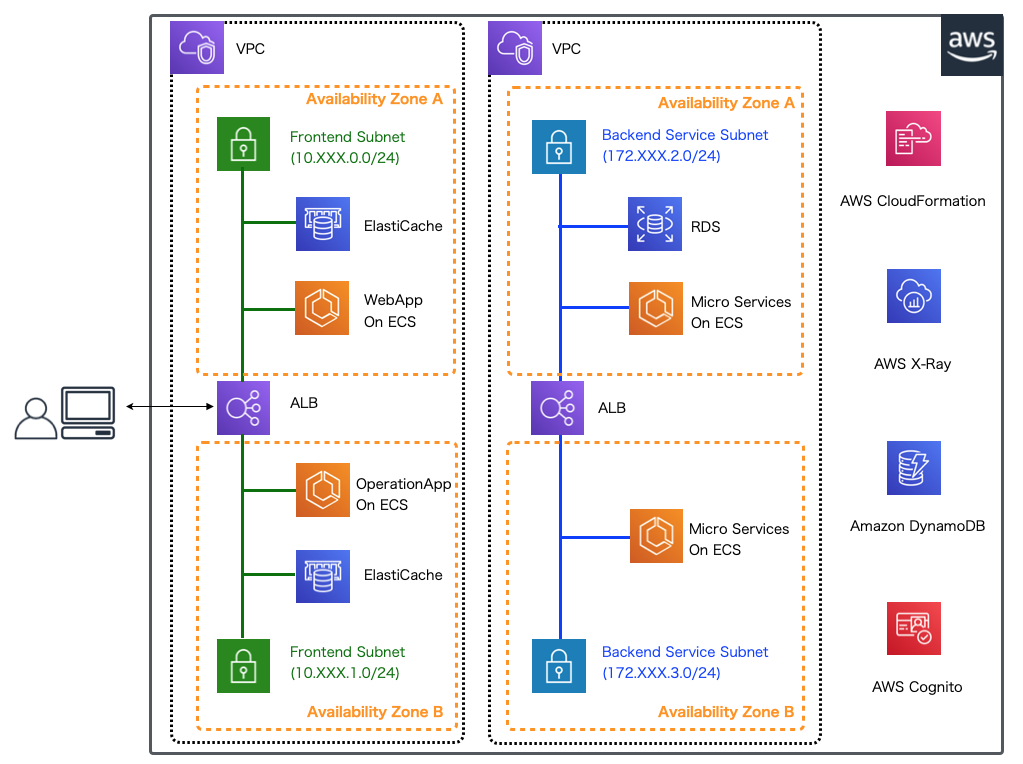
前回はX-Rayデーモンへトレースデータを送信するためのフロントエンドのWebアプリケーションの設定を個別に実装しました。 今回はバックエンドのマイクロサービスにおけるX-Rayの設定実装を解説していきます。 本連載で実際に作成するアプリケーションでは GitHub 上にコミットしています。 以降に記載するソースコードでは、import文など本質的でない記述を省略している部分があるので、実行コードを作成する際は、必要に応じて適宜GitHubにあるソースコードも参照してください。
サンプリングルールの設定¶
前回と同様、共通のX-Rayの設定クラスで、クラスパス配下にある、サンプリングルールを設定したsampling-rules.jsonを読み込んでいます。 ここでも、全てのリクエストが計測対象となるよう、レートを1に設定しておきます。サンプリングルールは対象のホストやHTTPメソッド、URLパスなど細かい設定が可能です。 詳細は サンプリングルールの設定 を参照してください。
{
"version": 2,
"rules": [
{
"description": "Sample description.",
"host": "*",
"http_method": "*",
"url_path": "/api/*",
"fixed_target": 1,
"rate": 1
}
],
"default": {
"fixed_target": 1,
"rate": 0.1
}
}
バックエンドのマイクロサービスにおけるX-Rayの設定¶
計測するサブセグメントとして、フロントエンドのWebアプリケーションと同様、Controller、Service、Repositoryごとに実行時間を計測します。前回設定したXRayConfigクラスのAOPポイントカット定義に基づき、各コンポーネントの実装クラスに@XRayEnabledアノテーションを付与します。 下記はControllerにアノテーションを付与する例です。
package org.debugroom.mynavi.sample.aws.microservice.backend.user.app.web;
// omit
import com.amazonaws.xray.spring.aop.XRayEnabled;
// omit
@XRayEnabled
@RestController
@RequestMapping("api/v1")
public class BackendUserController {
// omit
}
ただし、Repositoryのクラスについては、org.springframework.data.repository.Repositoryインターフェースを継承しているので、特にアノテーションは設定する必要はありません。 これはXRayConfigの継承クラス com.amazonaws.xray.spring.aop.AbstractXRayInterceptorクラスが既にそのインターフェースをポイントカット定義しているため です。 代わりに、バックエンドのマイクロサービスは現状インメモリデータベースHSQLを使ってユーザ情報を取得しているので、以下の通りDataSourceを com.amazonaws.xray.sql.TracingDataSourcでラップして定義しておきます。
package org.debugroom.mynavi.sample.aws.microservice.backend.user.config;
// omit
import com.amazonaws.xray.sql.TracingDataSource;
// omit
@Profile("dev")
@Configuration
public class DevConfig {
// omit
@Bean
public DataSource dataSource(){
return new TracingDataSource(new EmbeddedDatabaseBuilder()
.setType(EmbeddedDatabaseType.HSQL)
.addScript("classpath:schema-hsql.sql")
.addScript("classpath:data-hsql.sql")
.build());
}
}
最後にフロントエンドのWebアプリケーションの時と同じく、Controllerの処理が完了した後、TraceIDやユーザID、実行時間をDynamoDBに保存するよう、HanderInterceptorAdapterを継承したコンポーネントを生成します。 TraceIDは前回の実装と同様Segmentオブジェクトをcom.amazonaws.xray.AWSXRayから取得してもよいですが、リクエストヘッダにもTraceIDは設定されているため、そこから取得するように実装してみましょう。 最終的には、前回と同じくLogクラスに設定してDynamoDBへ保存します。
package org.debugroom.mynavi.sample.aws.microservice.backend.user.app.web.interceptor;
// omit
import org.apache.commons.lang3.StringUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import org.springframework.web.servlet.ModelAndView;
import org.springframework.web.servlet.handler.HandlerInterceptorAdapter;
import org.debugroom.mynavi.sample.aws.microservice.common.apinfra.cloud.aws.log.dynamodb.model.Log;
import org.debugroom.mynavi.sample.aws.microservice.common.apinfra.cloud.aws.log.dynamodb.repository.LogRepository;
import org.debugroom.mynavi.sample.aws.microservice.common.apinfra.util.DateStringUtil;
@Component
public class AuditLoggingInterceptor extends HandlerInterceptorAdapter {
private static final String HEADER_KEY = "X-Amzn-Trace-Id";
@Autowired(required = false)
LogRepository logRepository;
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response,
Object handler, ModelAndView modelAndView) throws Exception {
Log log = Log.builder()
.userId("1")
.traceId(getTraceId(request))
.createdAt(DateStringUtil.now())
.build();
logRepository.save(log);
}
private String getTraceId(HttpServletRequest request){
String header = request.getHeader(HEADER_KEY);
String[] headerElements = StringUtils.split(header, ";");
String rootElements = Arrays.stream(headerElements)
.filter(headerElement -> headerElement.startsWith("Root="))
.findFirst().get();
String[] traceIdElement = StringUtils.split(rootElements, "=");
return traceIdElement[1];
}
}
注釈
Webアプリケーションから送信されたリクエストに設定されているTraceIDはcom.amazonaws.xray.javax.servlet.AWSXRayServletFilterで取り出されて、バックエンドマイクロサービスのセグメントに設定されます。
実装が完了したら、双方のアプリケーションを起動して、同じくログイン処理を行ってみましょう。以下の通り、アプリケーション起動にかかる処理と、Webアプリケーションからマイクロサービスへの呼び出しが以下のように可視化されるはずです。
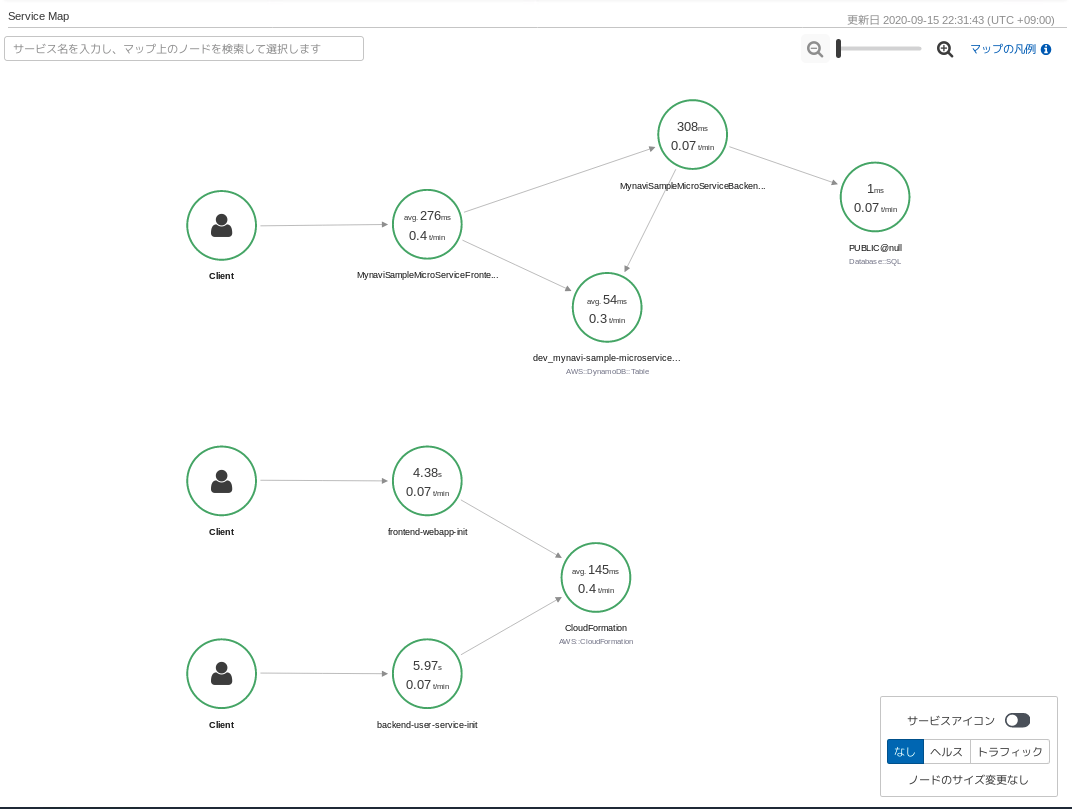
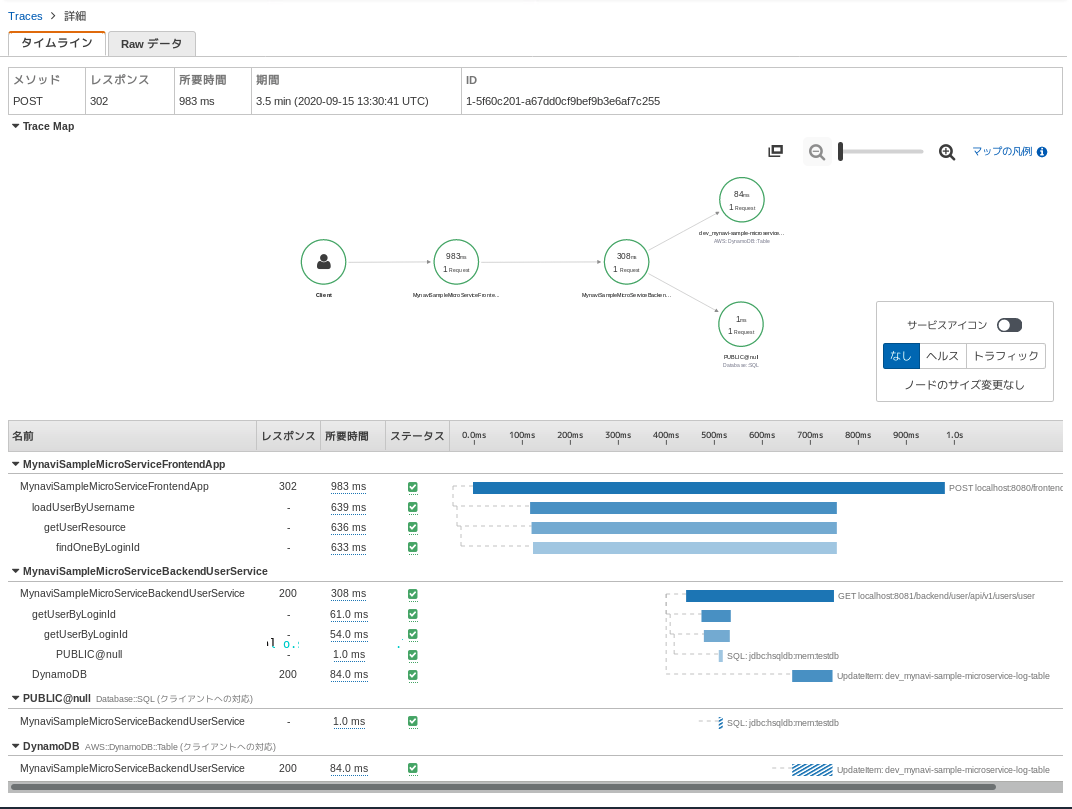
Webアプリケーションがバックエンドマイクロサービスにアクセスしてデータ取得し、認証を行う処理をトレースして可視化すると以下のようになります。 各コンポーネントの処理でどれくらい時間がかかっているのか、ビジネスロジックにほぼ手を加えることがなく可視化することができます。
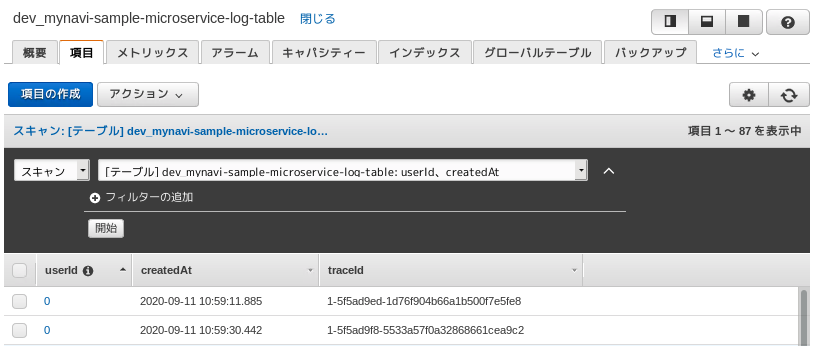
DynamoDBに保存したログは以下のようになります。ユーザIDやTraceIDなどで容易に検索しやすくなるので、必要に応じて保存する項目をカスタマイズするとよいでしょう。
以上、バックエンドのマイクロサービスにX-Rayを設定する実装を行い、フロントエンドのWebアプリケーションから呼び出して一連の処理の流れを可視化しました。 実装の初期から各処理を可視化して、性能上ボトルネックになりそうな箇所を早めに特定して、問題のあるものは必要に応じて改善し、製造していく中で品質を作り込む開発を心がけましょう。 次回以降はAWS Cognitoを使った、認証認可処理の組み込みやバックエンドのマイクロサービスに、アクセストークンによる認可制御を組み込んでいきます。
著者紹介¶
川畑 光平(KAWABATA Kohei) - NTTデータ エグゼクティブ ITスペシャリスト ソフトウェアアーキテクト・デジタルテクノロジーストラテジスト(クラウド)

金融機関システム業務アプリケーション開発・システム基盤担当、ソフトウェア開発自動化関連の研究開発を経て、デジタル技術関連の研究開発・推進に従事。
Red Hat Certified Engineer、Pivotal Certified Spring Professional、AWS Certified Solutions Architect Professional等の資格を持ち、アプリケーション基盤・クラウドなど様々な開発プロジェクト支援にも携わる。
AWS Top Engineers & Ambassadors 選出。
本連載記事の内容に対するご意見・ご質問は Facebook まで。